Code
# 导入库 | import libraries
import pandas as pd # 用于处理 DataFrame
import seaborn as sns # 用于快速画图表
import matplotlib.pyplot as plt # 用于处理和展示图表3.1 区分散点图 (scatter plot) 和 点图 (point plot)
**
多变量数据 Multivariate Data
**
本门课涉及的表格都是 tidy 、 flat 的表格。即, 每行 为一个 observation (或 instance** 或 record ) ,而 每列 为一个 attribute 或 variable (变量) 或 feature 或 parameter (参数) 。针对不同情况,可能使用不同的术语来称呼行和列。
通常,multivariate (多元的、多变量的) 用于描述 variable 超过两个的数据。即,multivariate plot 通常使用了原 DataFrame 中三个或三个以上的列作为数据。
根据之前学过的柱状图画法,除了 x, y 两个变量之外,我们还可以设置 hue 参数 ,从而实现绘制一个包含三个变量的柱状图。比如下图 Figure 1-1 中包含了 'island' , 'bogy_mass_g' , 'sex' 三个列的数据,即,三个变量的数据。
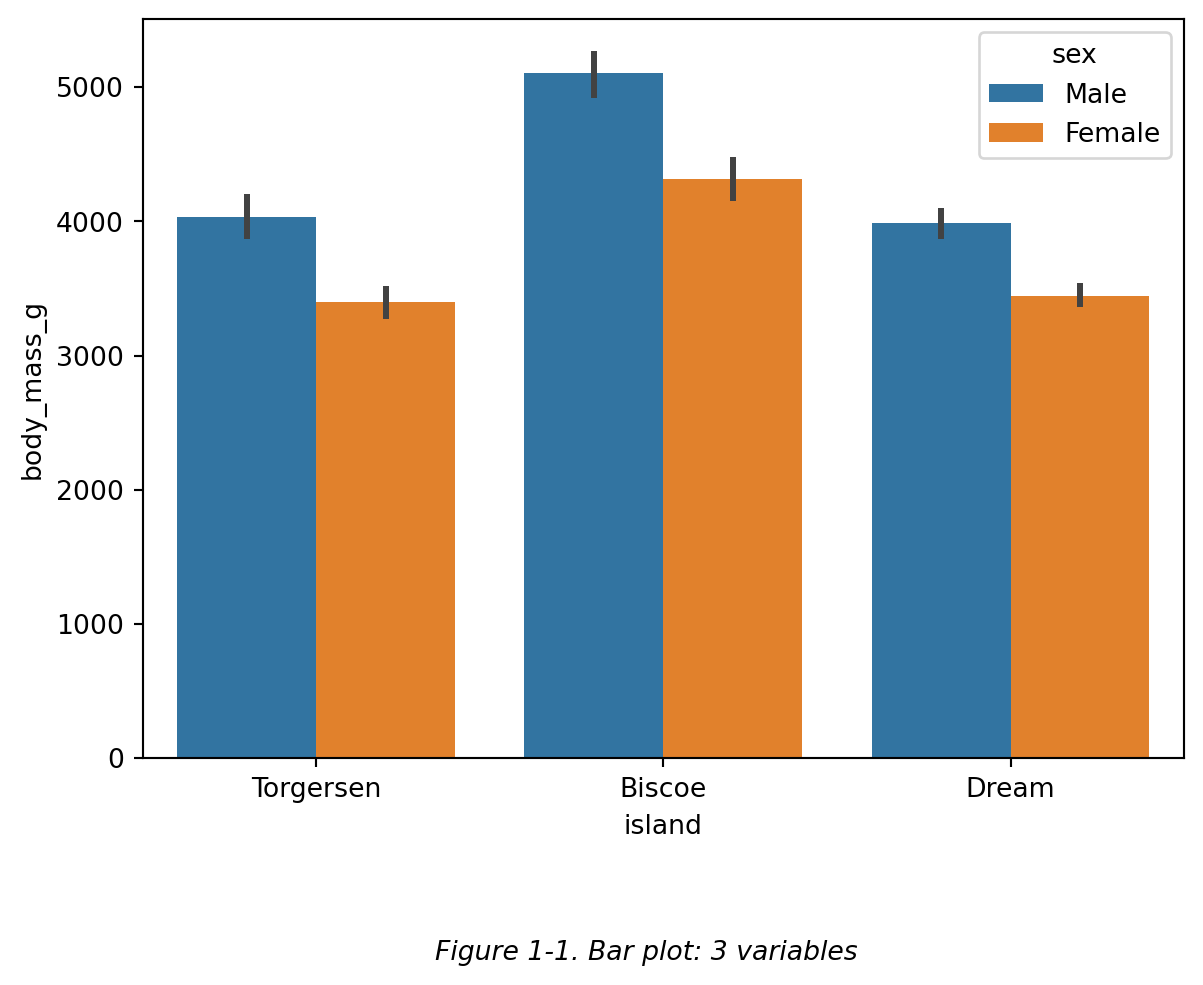
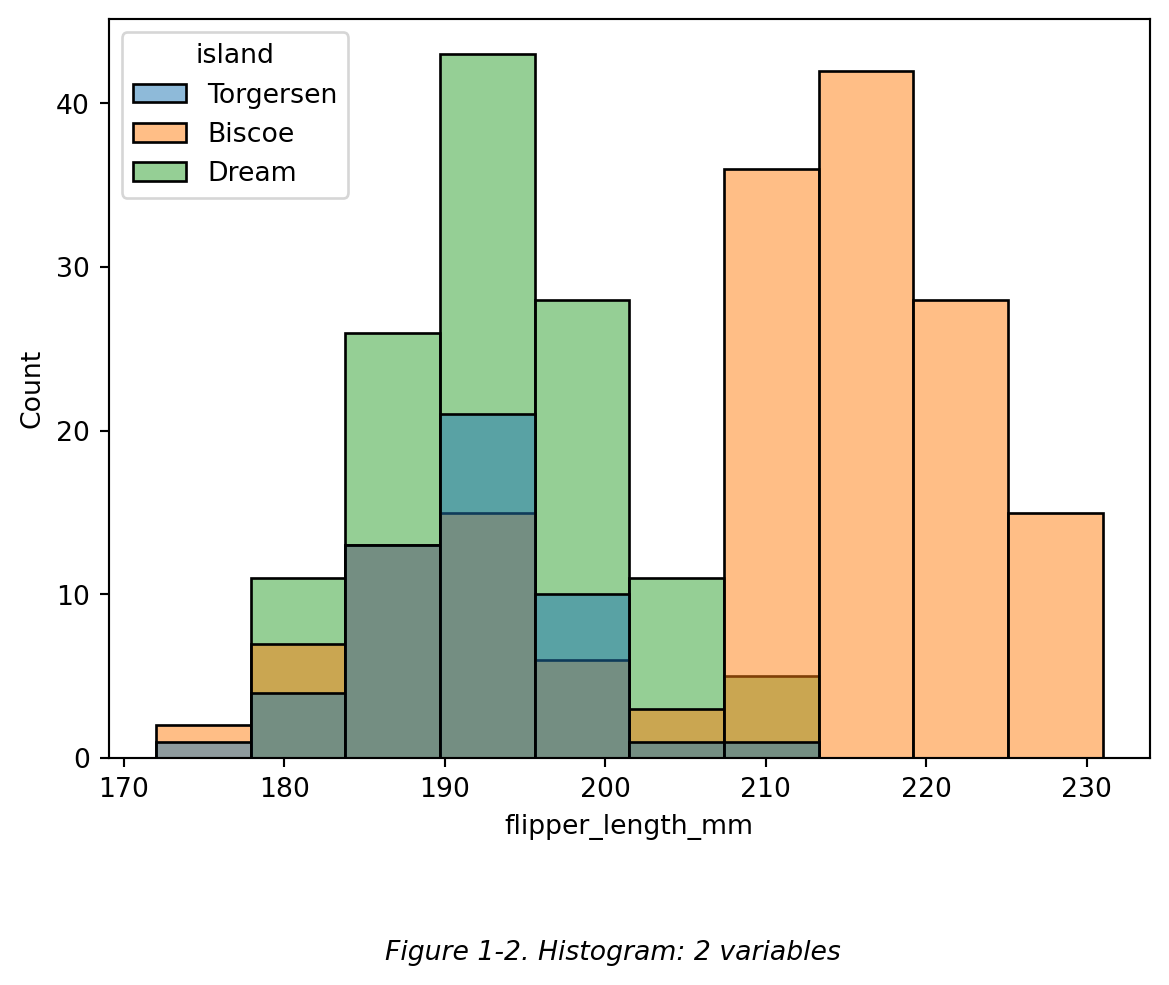
然而,有的图表类型不支持同时设置 x , y 和 hue 参数 来展示三个变量。比如直方图中,只支持 x 和 hue 参数的设置,见 Figure 1-2。直方图中 x 轴 和 y 轴展示的都是 ‘flipper_length_mm’ (鳍长)这个变量,x轴 展示的是鳍长的分布区间,y轴 展示的在鳍长的每个区间内,企鹅的量。因此这个直方图中只有两个变量(即原 dataframe 中的两个列)。
**
分面网格 Facetgrid
**
分面网格(facetgrid)是展示多元变量的一个常用方法。在一个分面网格中,若干个小图表将作为子图表,成网格状排列。一个子图表被称为一个分面 (facet),所有分面组成了一个分面网格 (facetgrid)。如果我们既想要展示直方图,又想要展示两个以上的变量,可以使用分面网格。
通过 Seaborn 绘制分面网格的方法如下:
# 创建分面网格 (facetgrid)
g = sns.FacetGrid(
data=df,
col='sex', # col: 设置网格的列。df 中'sex'列的数据有多少种,生成的网格就有多少列。
row='island', # row: 设置网格的行。同上,df 中一共有三个岛,所以生成的网格有三行。
)
# g: grid 网格
#【FacetGrid】
# FacetGrid 是由多个小图表组成的网格。
# 如下 (Figure 2-1) 是一个 3x2 (三行两列) 的 分面网格 (facetgrid)。
plt.figtext(0.5,-0.1,"Figure 2-1. Empty facetgrid",ha="center",fontsize=10,style='italic')
plt.show()
如 Figure 2-1,通过定义 g = sns.FacetGrid(data=df,col='sex',row='island') ,我们创建了一个包含许多小图表的网格。
但是此时只创建了网格,还需要通过 .map_dataframe() 方法来指定具体填充内容。
# 绘制完整的分面网格图
#【第一步】
# 创建分面网格
g = sns.FacetGrid(
data=df,
col='sex',
row='island',
hue='species', # 使用不同颜色来区分不同种类的企鹅
)
#【第二步】
# 指定要填充的内容
g.map_dataframe(
sns.histplot, # 画图要使用的函数,此处使用 sns.histplot 函数绘制直方图
x='flipper_length_mm', # 指定直方图中的 x 轴数据为鳍长
stat='density',
common_norm=False,
)
#【stat = 'density'】
# 用频率密度统计方法绘图,使直方图内所有 bar 的面积之和为 1。
#【common_norm = False】
# 配合 stat 参数使用。此处 False 意为: 在同一个小直方图中 (在一个分面中),
# 每种颜色的 bar 面积之和分别为 1,而非所有颜色的 bar 面积总和为 1
#【第三步】
# 添加并调整图例
g.add_legend() # 添加图例
sns.move_legend( # 调整图例
g,
loc='lower center',
bbox_to_anchor=(0.5,1),
ncol=3,
)
#【loc & bbox_to_anchor】
# 同时设置两个参数,让图例的下边缘中点 (lower center) 位于整个网格图的 (0.5,1) 位置
# 注:如果只设置了 loc = 'lower center',而没设置 bbox_to_anchor 参数的话,
# 图例将直接根据 loc 参数的值 'lower center' 定位于整个网格图的中下部。
#【ncol】
# number of columns:图例的列数
plt.figtext(0.5,-0.1,"Figure 2-2. Filled facetgrid",ha="center",fontsize=10,style='italic')
plt.show()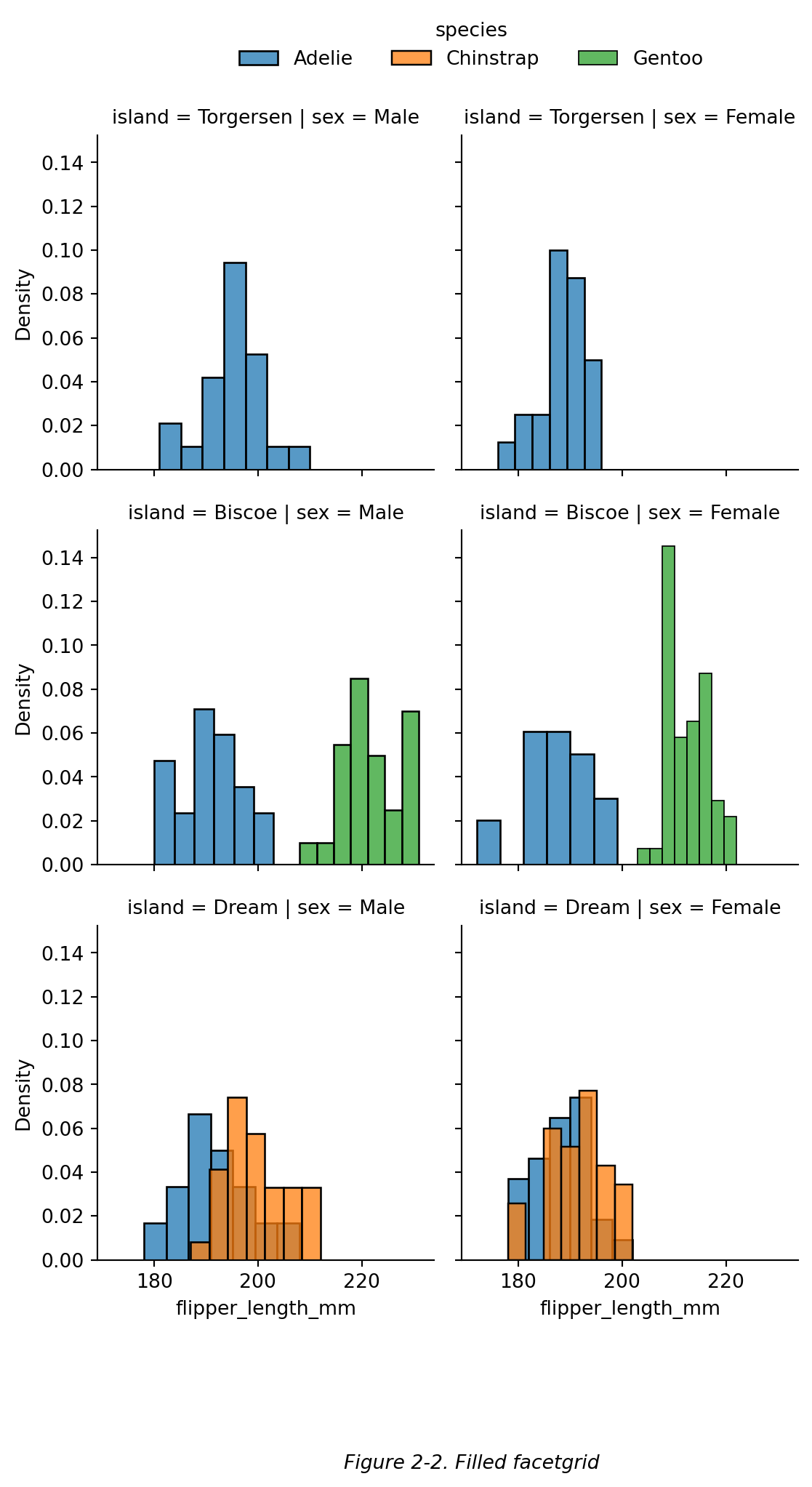
如 Figure 2-2,我们创建了一个分面网格,包含根据 鳍长 范围区间不同绘制了若干直方图,且按照 岛屿 不同进行了分行,按照 性别 不同进行了分列,按照 种类 不同进行了分色。由此可见,通过分行和分列,我们可以额外增加两个离散型变量;同时,通过区分颜色,可以再增加一个离散型变量。
注:由于分行和分列的特性,分面网格只能用于额外增加离散型变量。但可以给连续型变量划分区间,然后把不同区间范围保存为一个新的离散型变量(即,在 dataframe 中新增加一列),再用分面网格进行分行或分列。
此外,同时绘制多个小图表排列在一起展示(比如分面网格)时,需要注意 每个子表格的刻度范围应当相同。因为展示多图时,读者往往会默认它们的刻度范围是相同的;如果不相同,可能会造成误判,增加阅读困难 (Wilke, 2019, pp. 257-258)。
如下图 (Figure 2-3),每个小图表的纵坐标刻度范围各不相同,容易让人误判。

Figure 2-3. 差的多图刻度范围 (Wilke, 2019, p. 258)
将 Figure 2-3 中的图改成下图 (Figure 2-4) 这样所有刻度范围都相同,可以减少读者阅读困难。

Figure 2-4. 改良版多图刻度范围 (Wilke, 2019, p. 259)
**
散点图 Scatter Plot
**
**
3.1 区分散点图 (scatter plot) 和 点图 (point plot)
**
在画散点图 (scatter plot) 之前,需要注意区分 散点图 (scatter plot) 和 点图 (point plot) 。
>*
注:点图又称 dot plot (Wilke, 2019, p.43)。以下所有对于散点图与点图的区别的理解均基于 Seaborn 库,在其他语境下可能有所不同。
点图 (point plot) 可以起到类似柱状图或直方图的作用。点图每个点所在的竖线相当于柱状图的 bar 或直方图的 bin,而点图中的点则相当于柱状图中每个 bar 的顶边缘中点。像柱状图一样,点图可以用于展示 category-amount 型图表,比如下面两图 (Figure 3.1-1 和 Figure 3.1-2):
# 点图 (point plot) 示例:企鹅种类-喙长 category-amount
sns.pointplot(data=df, x='species',y='bill_length_mm',
linestyles='none') # 让点与点之间不要连线
# 绘制不同种类企鹅的鳍长平均值点图。比如所有 Adelie 企鹅的喙长平均值约为 39。Figure 3.1-1 中的竖线为误差线。
plt.figtext(0.5,-0.1,"Figure 3.1-1. Point plot: category-amount",ha="center",fontsize=10,style='italic')
plt.show()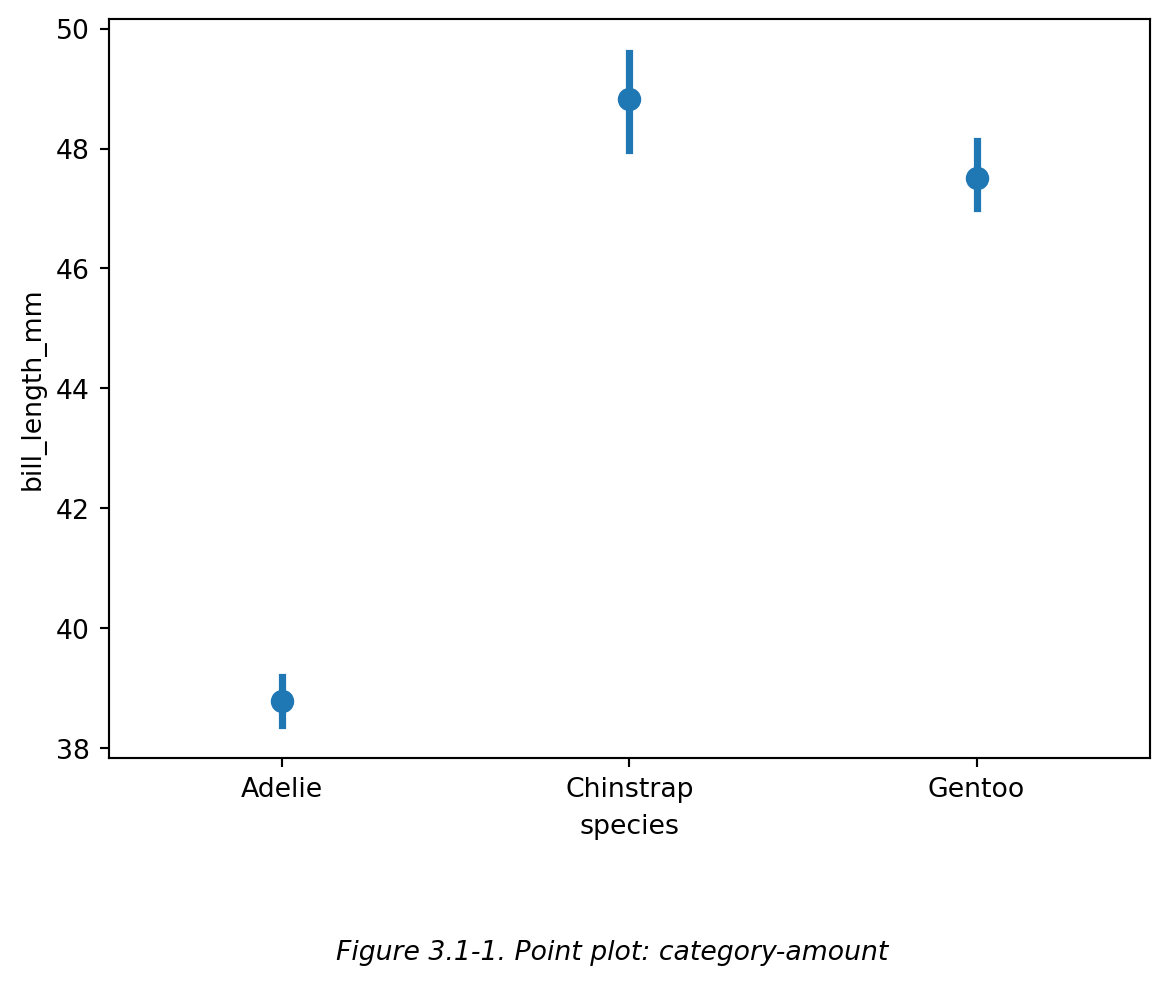
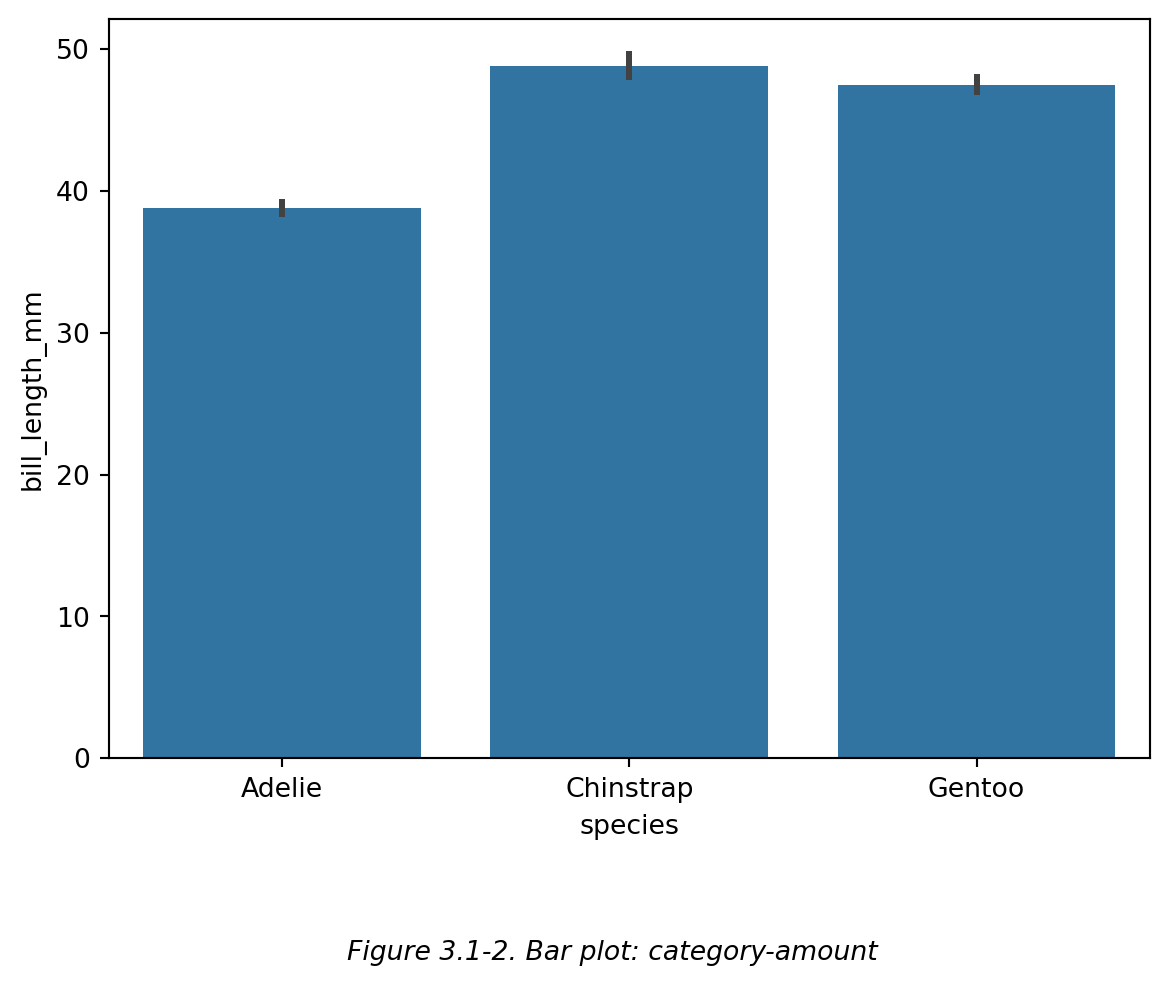
如上面两图 (Figure 3.1-1 和 Figure 3.1-2) 所示,点图 (point plot) 和 柱状图 都可以表示企鹅 企鹅种类-喙长 的关系,其中企鹅种类是 categorical data,而喙长是 numerical data,即 category-amount 的关系。这两种图的区别之一是,柱状图的 amount 必须从 0 开始,点图不需要从 0 开始。
需要注意的是,点图 (point plot) 和 柱状图 都只展示纵坐标的平均值(也可以自己设置为其他值,比如中位数)。因为在这两种图中,一个横坐标值只能对应一个纵坐标值。即,每个种类的企鹅只对应了一个显示其平均喙长的点/柱。
而 散点图 (scatter plot) 会显示每一个数据点。比如下面的图 (Figure 3.1-3):
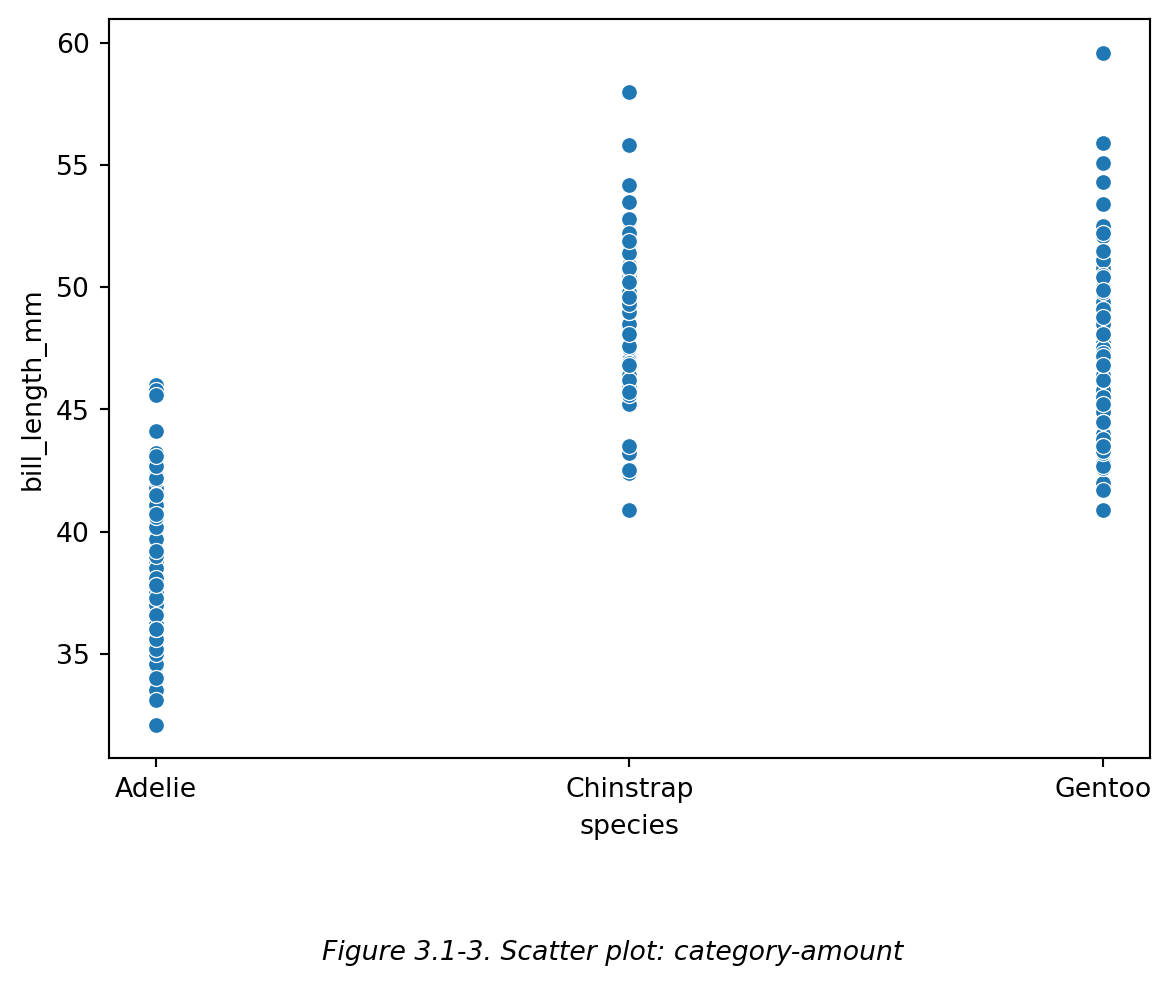
**
散点图 (scatter plot) 中每个横坐标可以对应许多纵坐标,而点图 (point plot) 中每个横坐标只能对应一个纵坐标。
**
此外,散点图 (scatter plot) 常用于探究两个(或多个)变量之间的关系 (relationship),查看变量间是否存在关联性 (correlation),最终可以用于分析二者间是否存在因果关系 (causation),主要用于探究两种连续的数值型数据之间的关系。因此,散点图横轴使用的数据通常为 ratio data,画图时横轴刻度会自动显示为连续的数值区间,比如 Figure 3.1-4:
# 散点图示例:企鹅喙长-喙深 ratio-ratio
sns.scatterplot(data=df,x='bill_length_mm',y='bill_depth_mm',alpha=0.7)
#【alpha】点透明度,填 0~1 的数字,1 是不透明,0 是全透明。
# ⭕注意:设置半透明的点可以帮助我们观察点的堆积,但是如果已经设置了按照渐变颜色区分某变量
# (如后文的 Figure 3.2-2),就不宜再使用半透明的点。
plt.figtext(0.5,-0.1,"Figure 3.1-4. Scatter plot: ratio-ratio",ha="center",fontsize=10,style='italic')
plt.show()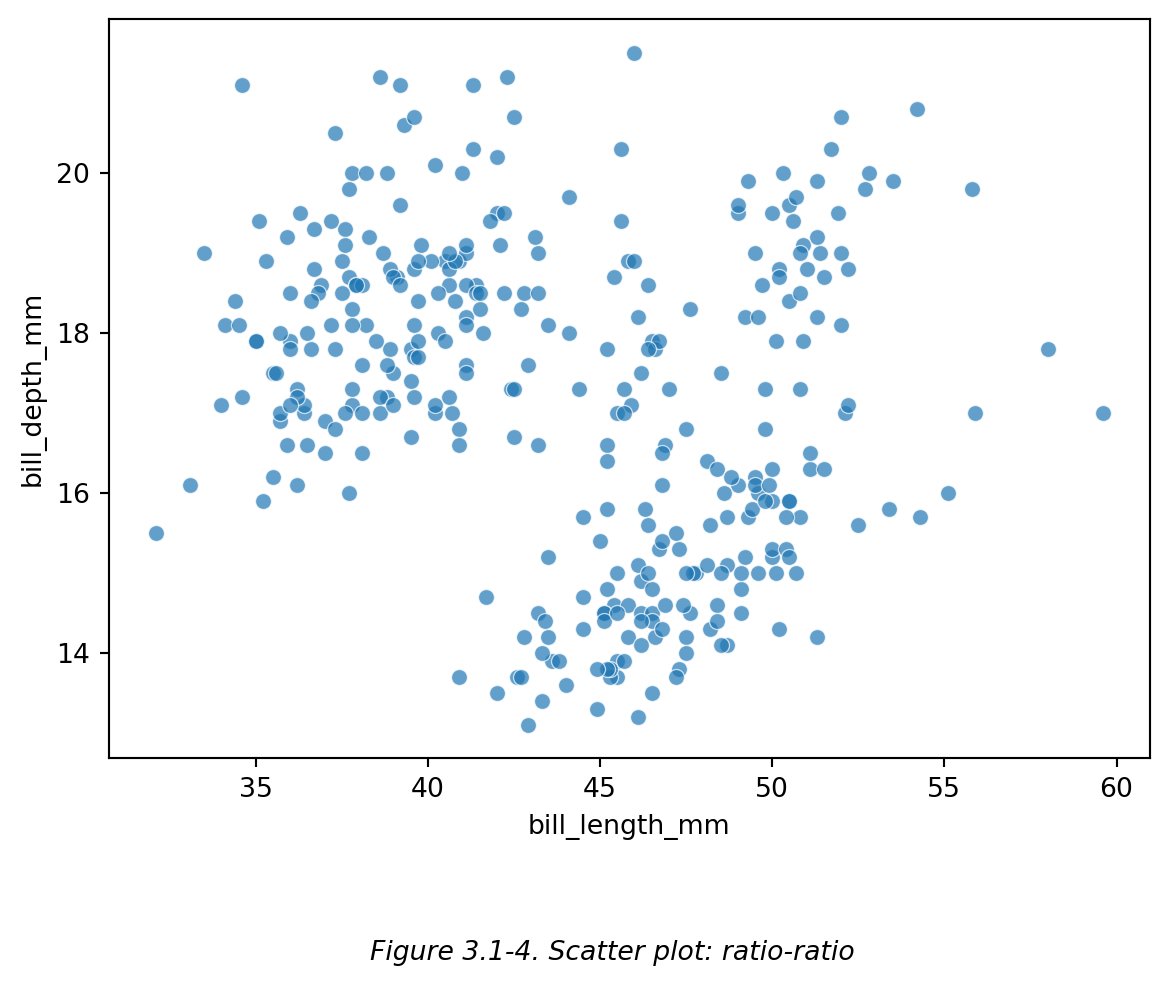
而画 点图 (point plot) 时,每一个点都会自动对应一个特定的横轴刻度,如果点图的横轴使用 ratio data,可能会产生如下效果 (Figure 3.1-5):
# 点图示例:企鹅喙长-喙深 ratio-ratio
sns.pointplot(data=df,x='bill_length_mm',y='bill_depth_mm',linestyle='none',errorbar=None,alpha=0.7)
# ⭕注:虽然 Figure 3.1-4 和 Figure 3.1-5 中点的分布看似很相似,但 Figure 3.1-5 中每个点
# 所在的横坐标有且仅有一个对应的点,Figure 3.1-4 的横坐标则可以对应多个点。此外,sns.pointplot()
# 函数不支持调整点的大小,而 sns.scatterplot() 函数支持。
plt.figtext(0.5,-0.1,"Figure 3.1-5. Point plot: ratio-ratio",ha="center",fontsize=10,style='italic')
plt.show()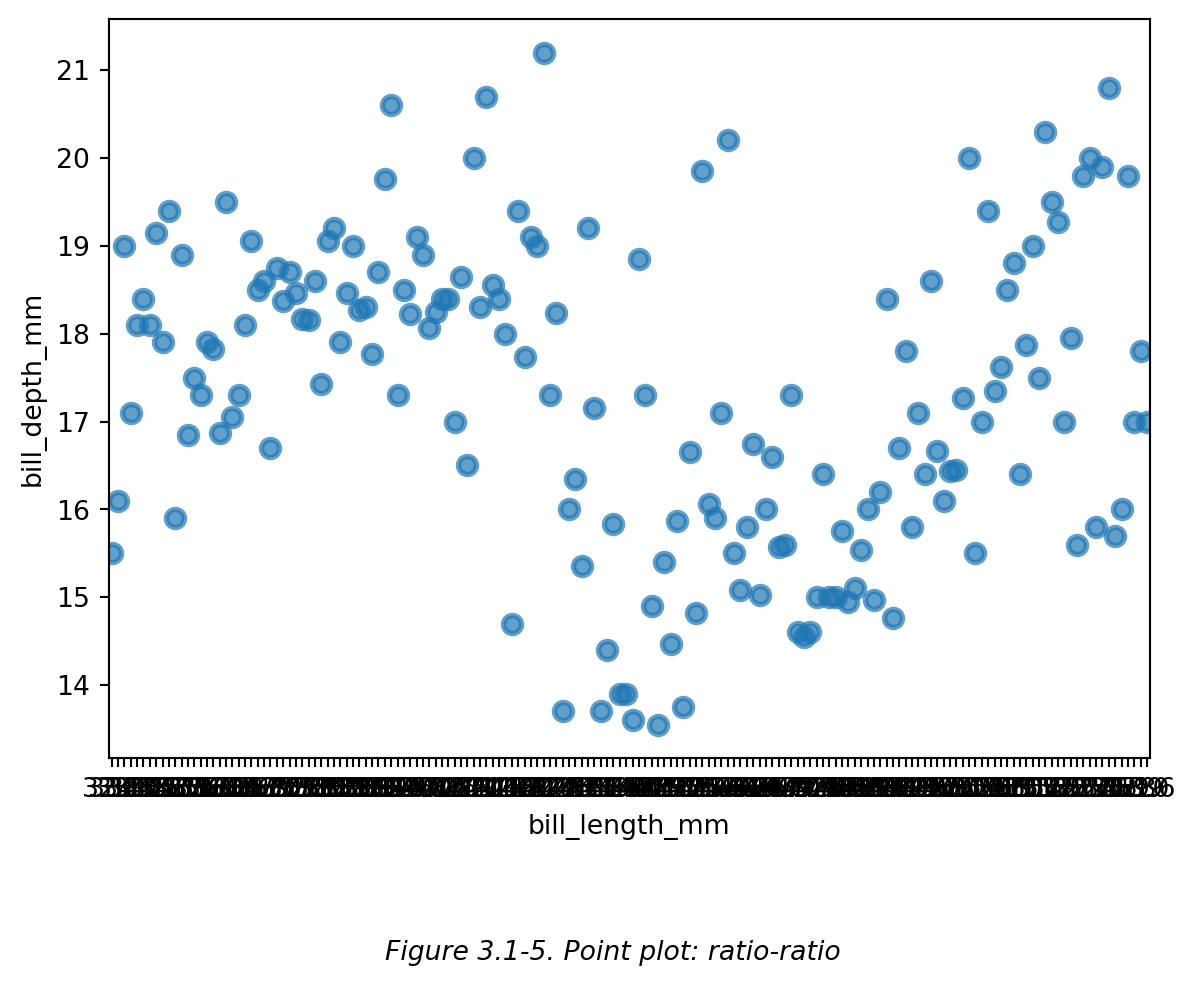
因此,点图 (point plot) 不适用 于展示 横坐标为连续型数据,且横坐标值过多 的数据,而更 适用于 展示 横坐标为离散型数据 的数据,且横坐标刻度不宜过多。
散点图 (scatter plot) 则相反,更适用于 ratio-ratio 数据的展示,即,横纵坐标都是连续型数值数据。
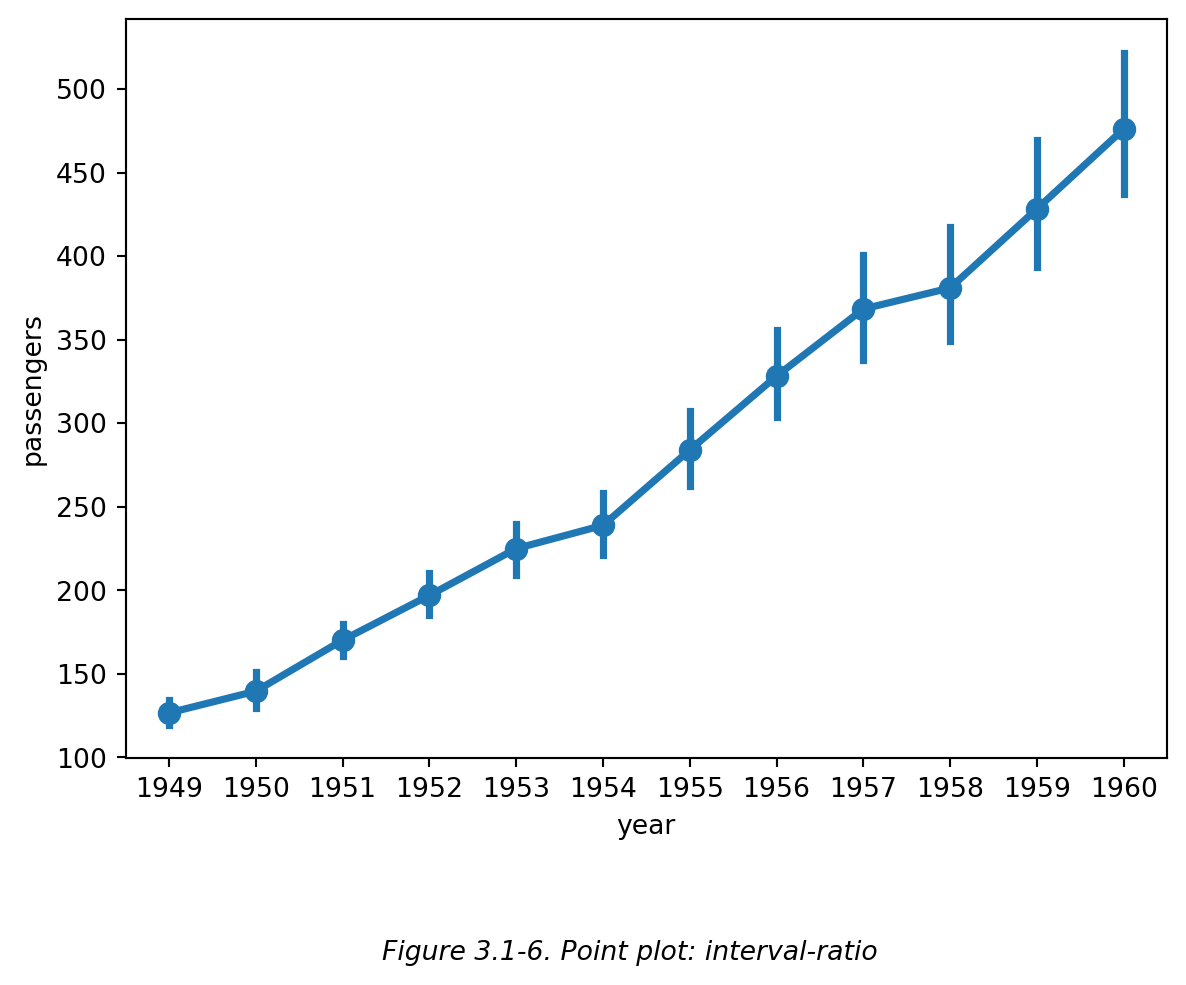
点图 (point plot) 的另一个特点是点与点之间可以连线,适用于横轴为 ordinal 或 interval data 数据的展示。因为当横轴刻度的顺序有意义时,连线才有讨论价值。比如下图 (Figure 3.1-6) 的年份即为 interval data,年份逐渐增加,连线可以表示年平均乘客量遂年份增加的变化趋势;而上面 Figure 3.1-1 中的点图的横坐标为企鹅种类,是 norminal data,其顺序没有意义,因此没有画连线。
而这种点图,变得和折线图非常非常类似。我们将在后续章节 4. 折线图 Line Plot 中继续讨论。
**
3.2 多变量散点图 Multivariate Scatter Plot
**
除了散点图的 x , y 轴展示的两种连续变量之间的关系之外,我们还可以通过设置 hue (点颜色),size (点大小),style (点形状) 等 参数,来给散点图设置其他变量。
**
以上这三个参数都可以应用于离散型变量,然而其中只有 hue 和 size 可以应用于连续型变量,因为点颜色和大小都可以连续渐变,点形状却不可以(仅限 Seaborn 库中)。
**
比如下图 (Figure 3.2-1):
# 增加离散变量:hue & size & style
ax = sns.scatterplot(
data=df,x='bill_length_mm',y='bill_depth_mm', # 散点图:企鹅喙长-喙深
hue='sex', # 用颜色区分企鹅性别
size='island', # 用点大小区分企鹅所在岛屿
style='species', # 用点形状区分企鹅种类
)
sns.move_legend(ax,loc='upper left',bbox_to_anchor=(1,1)) # 移动图例
plt.figtext(0.5,-0.1,"Figure 3.2-1. Adding discrete variables: hue & size & style",
ha="center",fontsize=10,style='italic')
plt.show()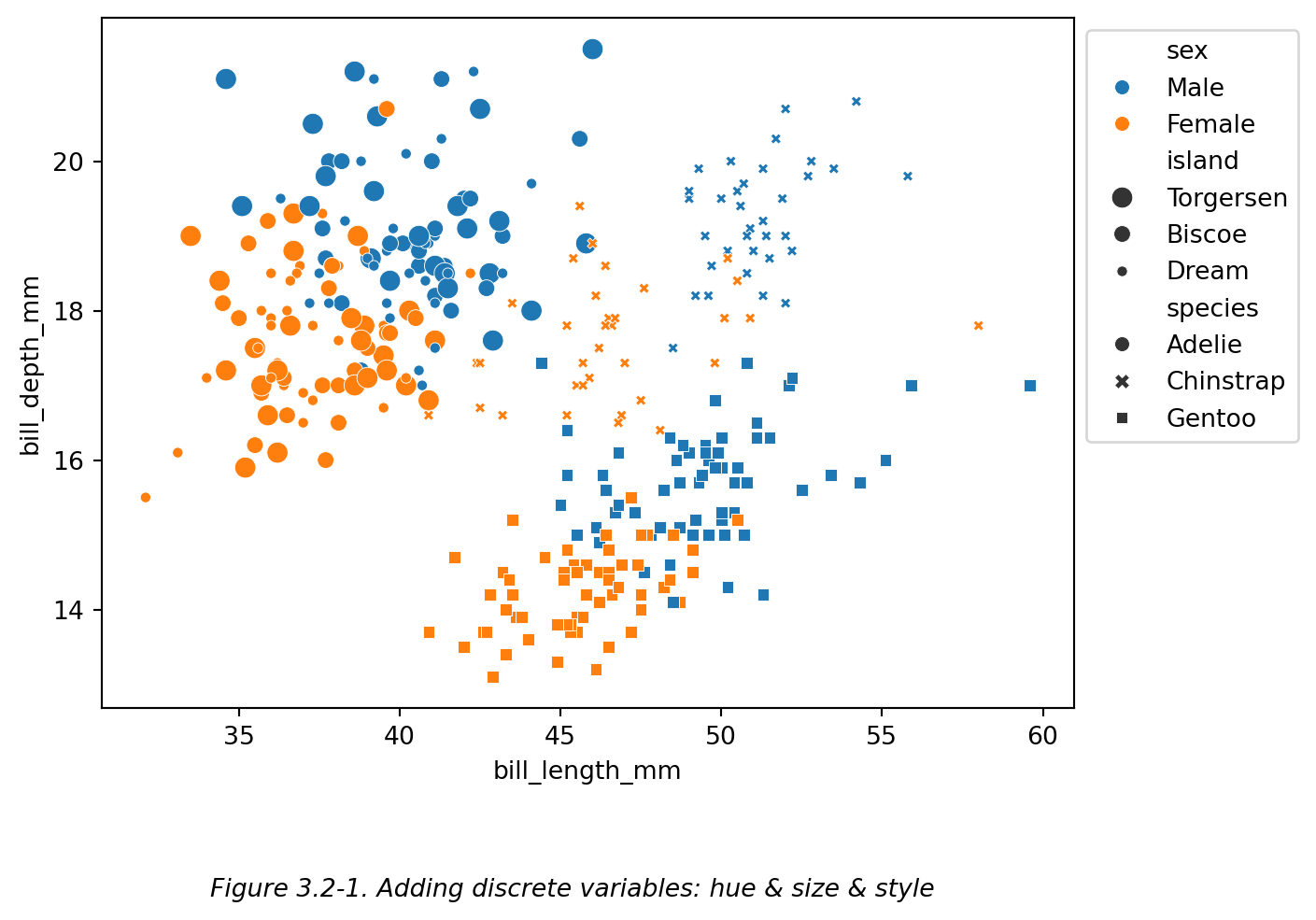
Figure 3.2-1 中,除了横纵轴使用了两个连续变量(喙长 和 喙深)之外,还设置了三个离散变量(性别、岛屿 和 种类)。
再比如下图 (Figure 3.2-2):
# 增加连续变量:hue & size
ax = sns.scatterplot(
data=df,x='bill_length_mm',y='bill_depth_mm', # 散点图:企鹅喙长-喙深
hue='flipper_length_mm',
size='body_mass_g', # 用点大小区分企鹅体质量
)
#【⭕注意】
# 如上文的 Figure 3.1-4 的代码块中提及,像本图 (Figure 3.2-2),
# 已经设置了按照渐变颜色区分鳍长,则不宜再使用半透明的点,因为透明度会影响颜色的展示。
sns.move_legend(ax,loc='upper left',bbox_to_anchor=(1,1)) # 移动图例
plt.figtext(0.5,-0.1,"Figure 3.2-2. Adding continuous variables: hue & size",
ha="center",fontsize=10,style='italic')
plt.show()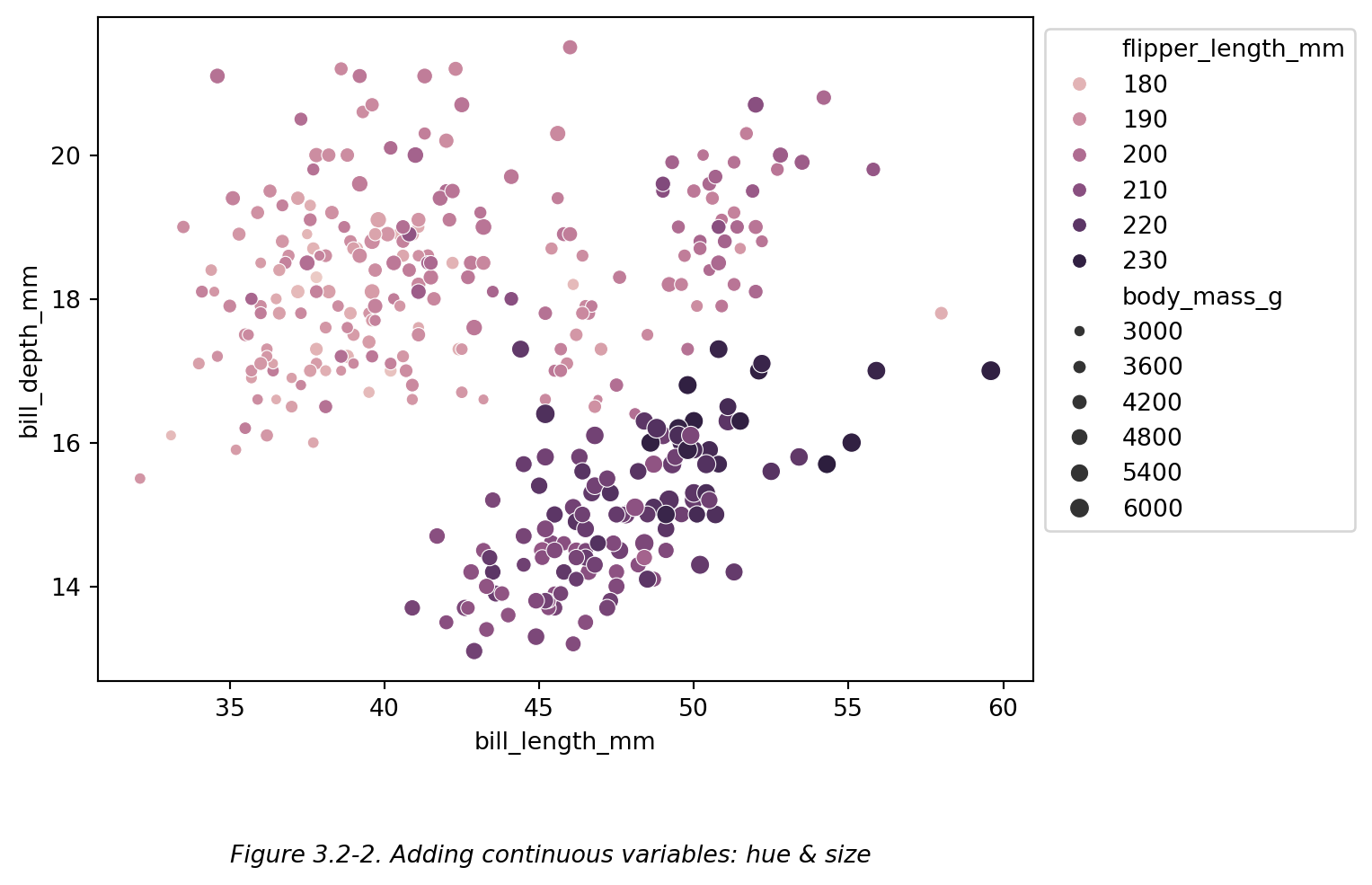
Figure 3.2-2 中,除了横纵轴使用了两个连续变量(喙长 和 喙深)之外,还设置了两个连续变量(鳍长 和 体质量)。
注:虽然 hue 和 size 可以应用于 ratio data 列(即,可以应用于连续变量),但是其图例并非严格连续的。
总地来说,和分面网格相比,多变量散点图的优点有:
然而,多变量散点图也存在局限性:
在多变量散点图中,对点大小的区分非常微妙,读者难以辨认;而对颜色的区分,也可能令读者难以辨认 (比如 浅绿色 和 绿色 ),尤其是患有色觉缺陷的读者。
因此,为了让散点图更易懂,我们可以 同时使用颜色和形状区分一个变量 (Wilke, 2019, pp.243-247)。比如下图 (Figure 3.2-3):
# 同时使用 hue 和 style 控制 岛屿 变量
ax = sns.scatterplot(
data=df,x='bill_length_mm',y='bill_depth_mm', # 散点图:企鹅喙长-喙深
hue='island',
style='island',
)
sns.move_legend(ax,loc='upper left',bbox_to_anchor=(1,1)) # 移动图例
plt.figtext(0.5,-0.1,"Figure 3.2-3. Hue & style: controlling the same variable 'island'",
ha="center",fontsize=10,style='italic')
plt.show()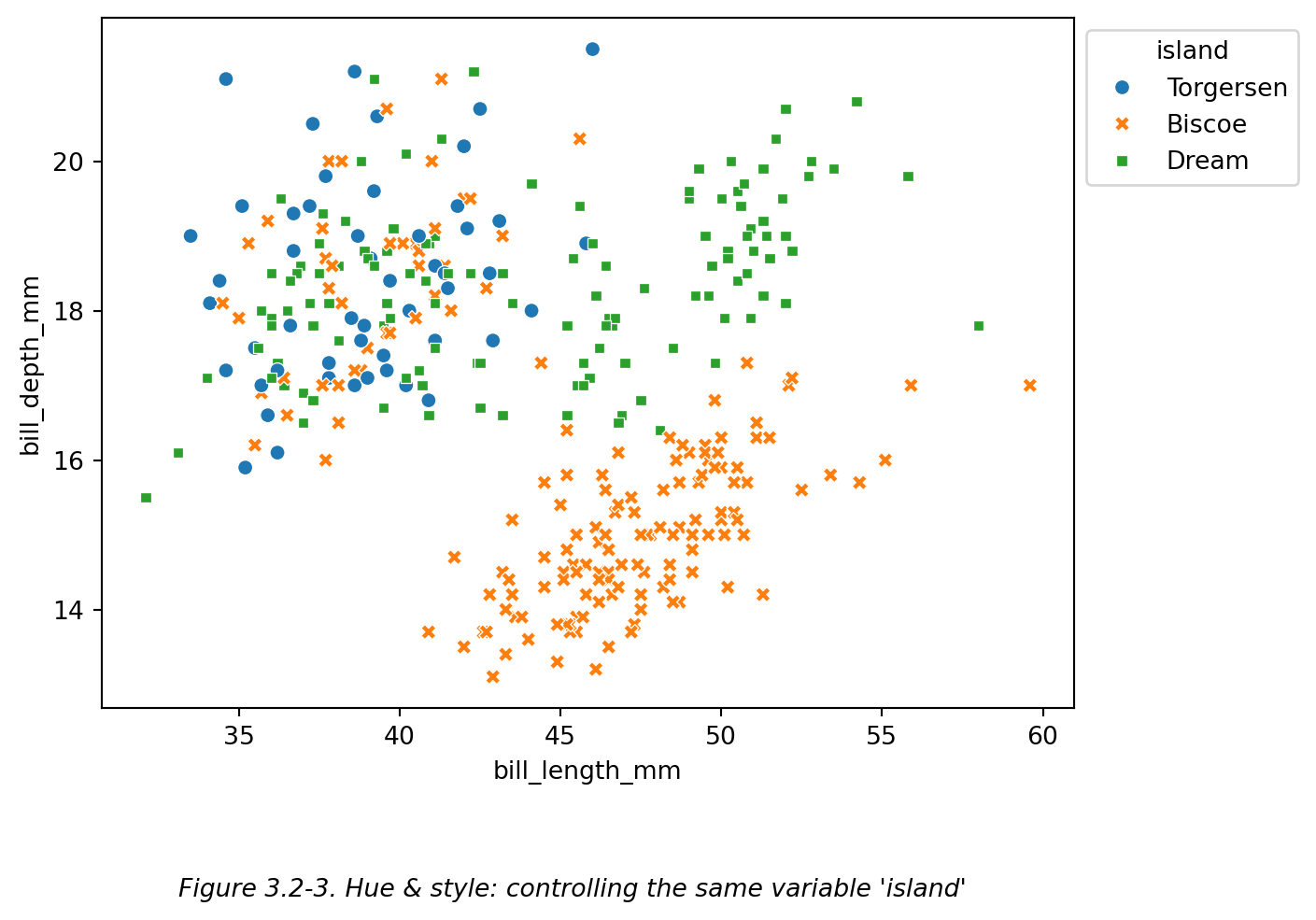
如 Figure 3.2-3 所示,同时用点颜色和点形状对于岛屿进行了区分,有助于读者理解。
此外, 尽量不要在同一个图表内使用 style 和 size 控制 两个变量,因为当形状改变了之后,大小的区分变得不够直观。比如下图 (Figure 3.2-4):
# 同时使用 (hue + style) 和 size 控制 岛屿 和 鳍长 两个变量
ax = sns.scatterplot(
data=df,x='bill_length_mm',y='bill_depth_mm', # 散点图:企鹅喙长-喙深
hue='island',
style='island',
size='flipper_length_mm', # 在 Figure 3.2-3 的基础上增加了对于点大小的区分
)
sns.move_legend(ax,loc='upper left',bbox_to_anchor=(1,1)) # 移动图例
plt.figtext(0.5,-0.1,"Figure 3.2-4. Size: controlling another variable 'flipper_length_mm'",
ha="center",fontsize=10,style='italic')
plt.show()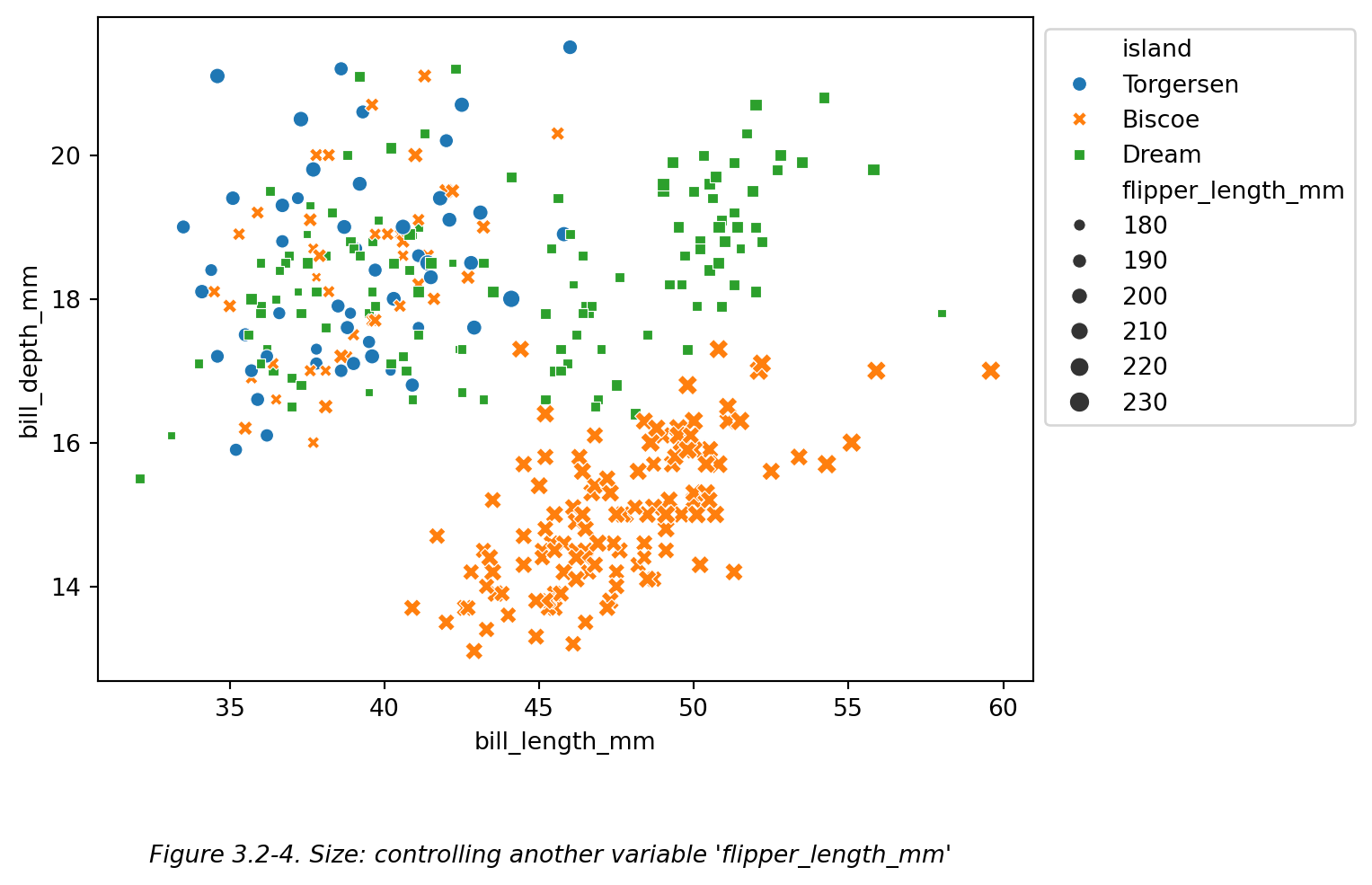
还有一些其他细节需要注意:
这些细节我们将在后续章节 4. 折线图 Line Plot 中继续深入讨论。
**
3.3 对数尺度 Logarithmic Scales
**
对数尺度 (logarithmic scale) 是一个非线性的测量尺度,适用于有较大范围差异的数据。比如里氏地震震级、声学中的音量、光学中的光强度、及溶液的PH值等。为这类数据绘制散点图时,可以将坐标轴使用的刻度尺度设置为对数尺度(默认为线性尺度,如 Figure 4 中横坐标为 35, 40, 45, 50… 是线性增长的数字),这样会让原本拥挤的数据点变得较为分散、均匀,更容易观察。(维基百科 - 对数尺度)
Wilke (2019, p.17) 使用 \((1, 3.16, 10, 31.6, 100)\) 这组数据作为例子画了四个数轴 (Figure 3.3-1)。其中:
> \(10 ^ {0.5} = \sqrt{10} \approx 3.16\)
> \(10^{1.5} = 10 \times 10^{0.5} \approx 31.6\)

Figure 3.3-1. 四个数轴 (Wilke, 2019, p.17)
如 Figure 3.3-1 所示:
第一个数轴使用了线性尺度,刻度为 \((0, 25, 50, 75, 100)\),数据点不均匀地分布在数轴上,每个点代表对应的 x 的数值。每个点的值分别为:\(1, 3.16, 10, 31.6, 100\) 。
第二个数轴 同样使用了线性尺度,刻度为 \((0.0, 0.5, 1.0, 1.5, 2.0)\) ,但是在原数据的基础上 进行了取对操作。第二个数轴中每个点代表 x 的对数,即 $ log_{10}(x) $ (或 “$ lg(x)$” )。每个点的值分别为:\(0.0, 0.5, 1.0, 1.5, 2.0\) 。此时每个数据点代表的数值 已经不是原数据,而是其对数,因此第二个数轴的标签为 “ $ log_{10}(x) $ ” 。
第三个数轴 仍然使用了原数据 ,但是对于轴的尺度进行了调整——改用了对数尺度,刻度为 \((1, 3.16, 10, 31.6, 100)\) ,约等于 $ (10^{0.0} \(,\) 10^{0.5} \(,\) 10^{1.0} \(,\) 10^{2.0}) $ 。
第一个数轴和第三个数轴对比来看,对于同一组数据,轴刻度使用了不同尺度(线性尺度 v.s. 对数尺度),数据点在轴上的排布发生了变化——线性尺度轴中分布不均匀的点,在对数尺度轴中变得均匀。这样调整数轴的刻度,有助于我们观察分布不均匀的数据,尤其是呈现指数型增长趋势的数据(i.e. 先增长得很慢、数据点挤在一起;后增长得很快,数据点间距突增)。
**
需要注意的是,改用对数尺度后,只是让轴刻度的展示方式变了,数据点的位置有所变化,但并没有改变数据点的值。
**
也就是说,第一个数轴和第三个数轴展示的都是原数据 x,而只有第二个数轴展示的是 x 的对数。
因此,对于像第三个数轴这样的 仅改用刻度尺度 但不改动原数据 的图而言,不可以将轴标题写作 “ $ log_{10}(x) $ ” (见第四个数轴)。
总地来说,当数据的分布具有以下特性时,用对数尺度来表示轴刻度会更方便观察:
* 数据有数量级差异时,使用对数尺度可以同时显示很大的数值和很小的数值。
* 数据有指数型增长趋势时,使用对数尺度可以将曲线变为直线表示。
例如,下图 (Figure 3.3-2) 中使用的数据范围差异较大且左边过于集中、右边过于空旷——可以考虑使用对数尺度的坐标轴 (Figure 3.3-3)。
# 用 seaborn 中的另一个示例数据集 'planets' 作为演示
# 展示 “行星到地球的距离” 和 “行星的质量” 之间的关系
planets = sns.load_dataset('planets')
g = sns.scatterplot(data=planets, x='distance', y='mass')
plt.title('Relationship between planetary distance and mass')
plt.figtext(0.5,-0.1,"Figure 3.3-2. Point plot: linear scale",ha="center",fontsize=10,style='italic')
plt.show()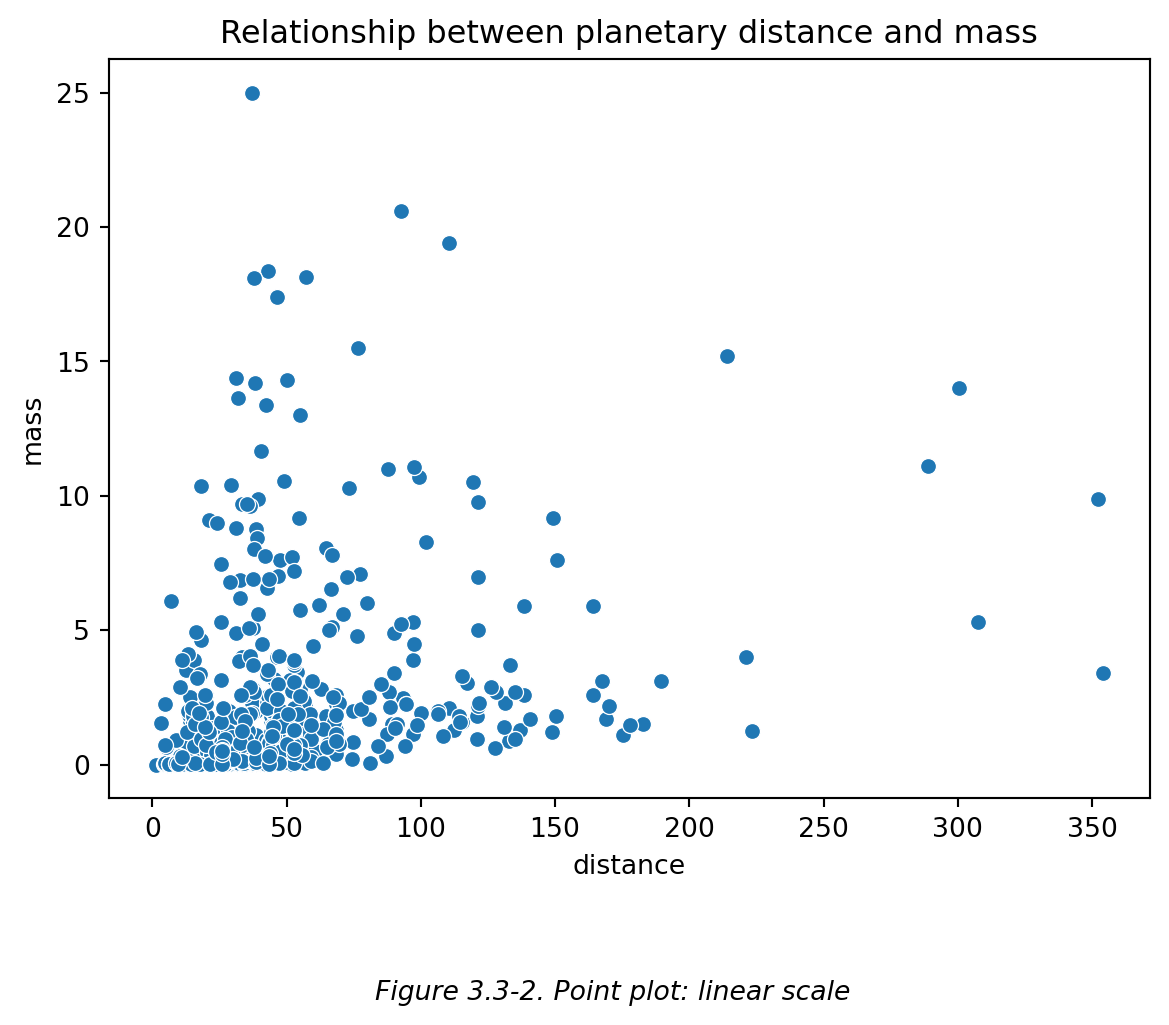
# 改用对数尺度重新画散点图
planets = sns.load_dataset('planets')
g = sns.scatterplot(data=planets, x='distance', y='mass')
# x/y 轴都设置对数刻度标尺
g.set_xscale('log') # 默认底数为 10,可以通过设置 base 参数来修改底数。
g.set_yscale('log')
plt.figtext(0.5,-0.1,"Figure 3.3-3. Point plot: logarithmic scale",ha="center",fontsize=10,style='italic')
plt.show()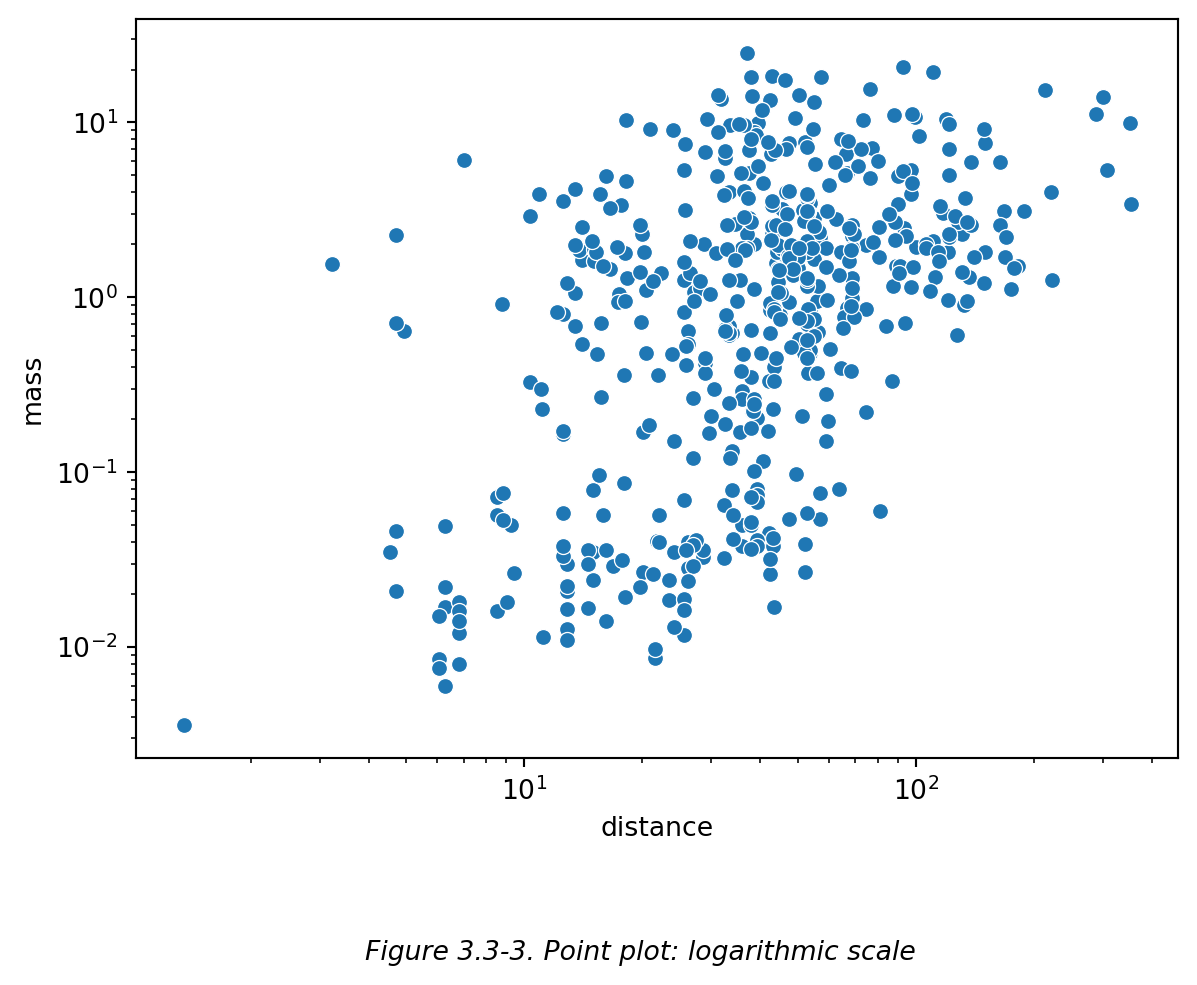
注意:
Figure 3.3-3 中,刻度 \((10^0, 10^1, 10^2, 10^3 ... 10^n)\) 是等距离的对数尺度刻度。而每两个大刻度中间的小刻度代表了等差的实际数值,比如从原点 (原点为 \(10^0\),即 1) 开始到 \(10^1\) 为止的九个小刻度分别代表了数字 \(2, 3, 4, ..., 8, 9\),从 \(10^1\) 到 \(10^2\) 之间的九个小刻度分别为 \(20, 30, 40, ..., 80, 90\),以此类推。
由于对数尺度的特性,对数尺度轴上没有 0 值,而是以 1 (即底数的 0 次方) 为原点,其正半轴为大于 1 的数,负半轴为大于 0 小于 1 的数。因此,对数尺度适合用于展示一些比例数据。比如 Wilke (2019, pp.18-20) 展示了一组数据记录了德克萨斯州每个县的人口数量,并将其除以德克萨斯州所有县的人口中位数,作为纵轴数据。利用对数尺度 (Figure 3.3-4),展现了德克萨斯州每个县人口数在中位数附近的分布情况,当比值为 1 的时候,说明该县的人口正好为中位数。

Figure 3.3-4. 德克萨斯州各县人口分布情况 - 对数尺度
然而,如果用线性尺度展示 Figure 3.3-3 中的数据的话,就会以 0 为原点,无法清晰展示数据在 1 两侧的分布情况,形成 Figure 3.3-5。

Figure 3.3-5. 德克萨斯州各县人口分布情况 - 线性尺度
总地来说,对数尺度的优点有:
* 压缩数据范围。 用于处理大范围数据,避免极大和极小数据因为距离相差甚远而难以展示和阅读。 * 使数据分布均匀。 避免大量数据点集中在特定范围内而难以阅读。 * 揭示指数增长趋势。 如果原数据呈现指数增长趋势,对数尺度会让数据呈直线关系,更容易发现变量之间的关联性。 * 突显相对差异。 当数据的绝对值非常大时,不同数据点之间的数量级差可能比绝对值差更有研究价值。比如 \(10^5\) 和 \(10^8\) 之间差了三个数量级。
而对数尺度也存在局限性:
* 不适用于零值和负值。 由于对数函数的定义,对数尺度轴中只有正数,没有 0 和 负数。
* 难以解读。 对数尺度图表不像线性尺度那样直观易懂,不熟悉对数尺度的读者可能难以解读对数尺度图表。
* 对于非指数关系的展示不直观。 如果数据本身的趋势并不符合指/对数关系,使用对数尺度可能会误导读者,掩盖其真实趋势。
**
3.4 回归图 Regression Plot
**
散点图通常用于探究两个(或多个)变量之间的数学关系,回归图 (regression plot) 则是将散点图拟合成一条线,用于展示两个变量之间的关系。最常见的拟合方式是线性拟合 (linear fitting),即,将散点图拟合成一条直线,这条线称作线性回归线 (linear regression line)。置信区间用于显示回归线(作为估计值)的不确定性,当置信水平为 95% 时,真实值有 95% 的可能落在这个区间内。Figure 3.4-1 中,直线是线性回归线,阴影部分是置信区间。
# 使用 sns.lmplot() 函数画一个包含线性拟合的散点图
sns.lmplot(data=df, x='bill_length_mm', y='bill_depth_mm', hue='sex')
#【lmplot】linear model plot
# 该函数默认的线性拟合方式是 'ci',即 置信区间 (confidence intervals)。
# 默认置信水平为 95%,即 “真实值有 95% 的概率落在这个区间内”,用于衡量估计值(即回归线)的不确定性。
# ⭕注:此函数仅适用于离散型数据。
plt.figtext(0.5,-0.1,"Figure 3.4-1. Regression Plot",ha="center",fontsize=10,style='italic')
plt.show()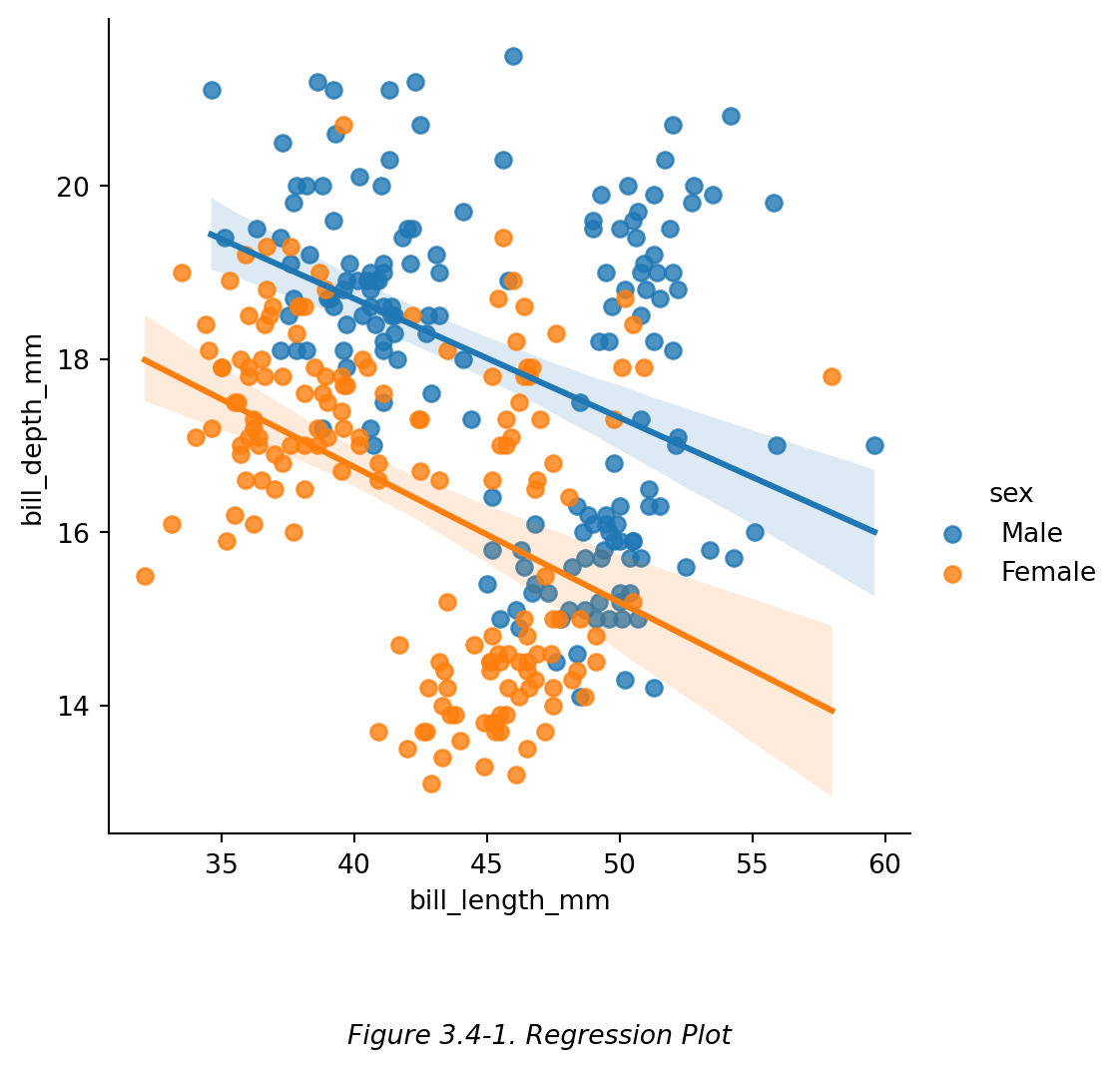
**
折线图 Line Plot
**
在散点图中,数据点以点的形式独立存在,显示变量之间的关系或分布。通常用于探索 两个变量 之间的相关性或分布情况。其数据点之间通常无先后关系。
而在折线图中,数据点通过线段连接,强调数据的连续性或变化趋势。因此折线图通常用于时间序列数据,强调 一个变量 随时间的变化趋势。其数据点之间存在先后关系。
如下图 (Figure 4-1),展示了某航空公司每月乘客量遂年份增长的变化:
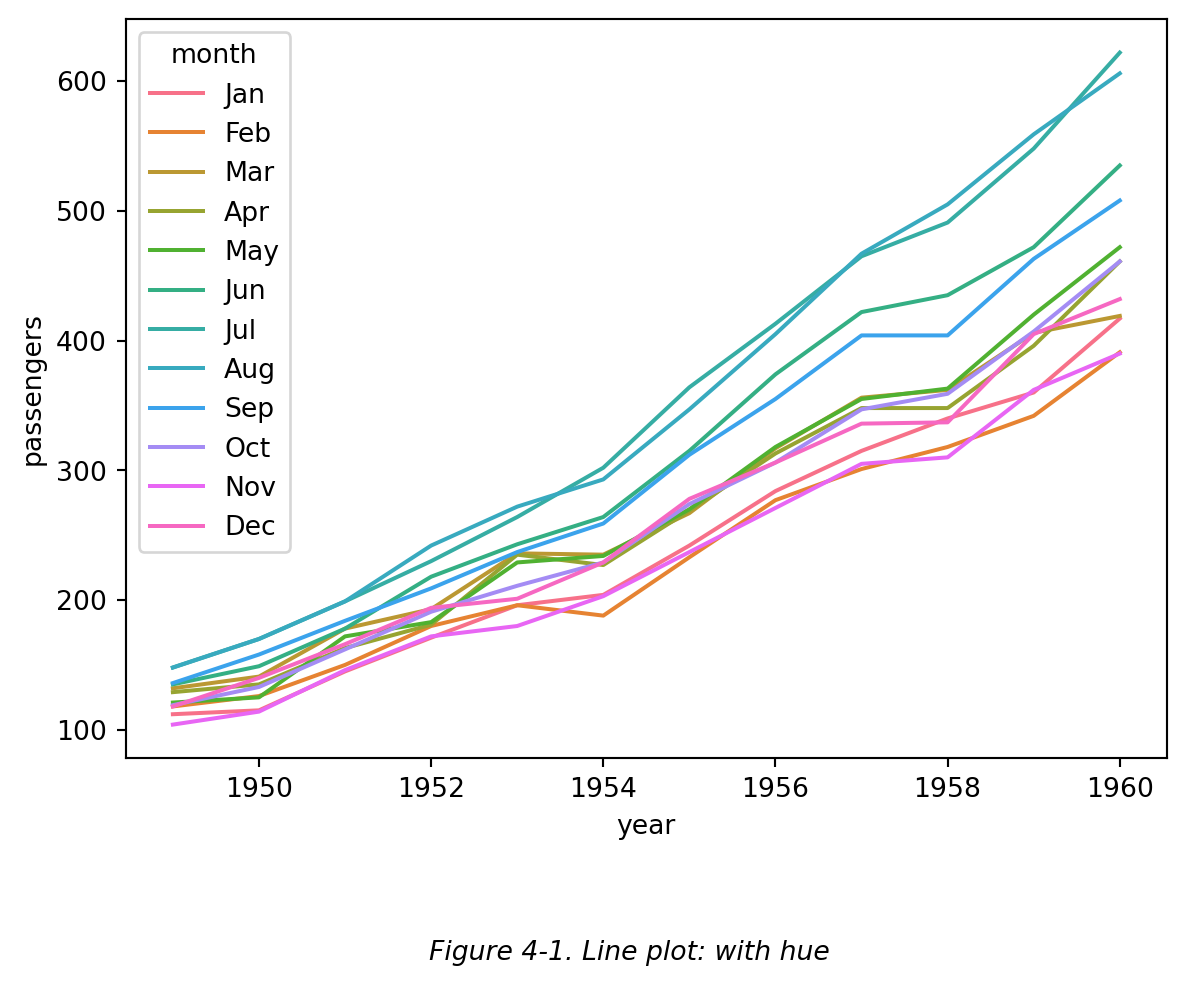
也可以通过设置 markers = True 和 dashes = False 来展示折点,如下图 (Figure 4-2):
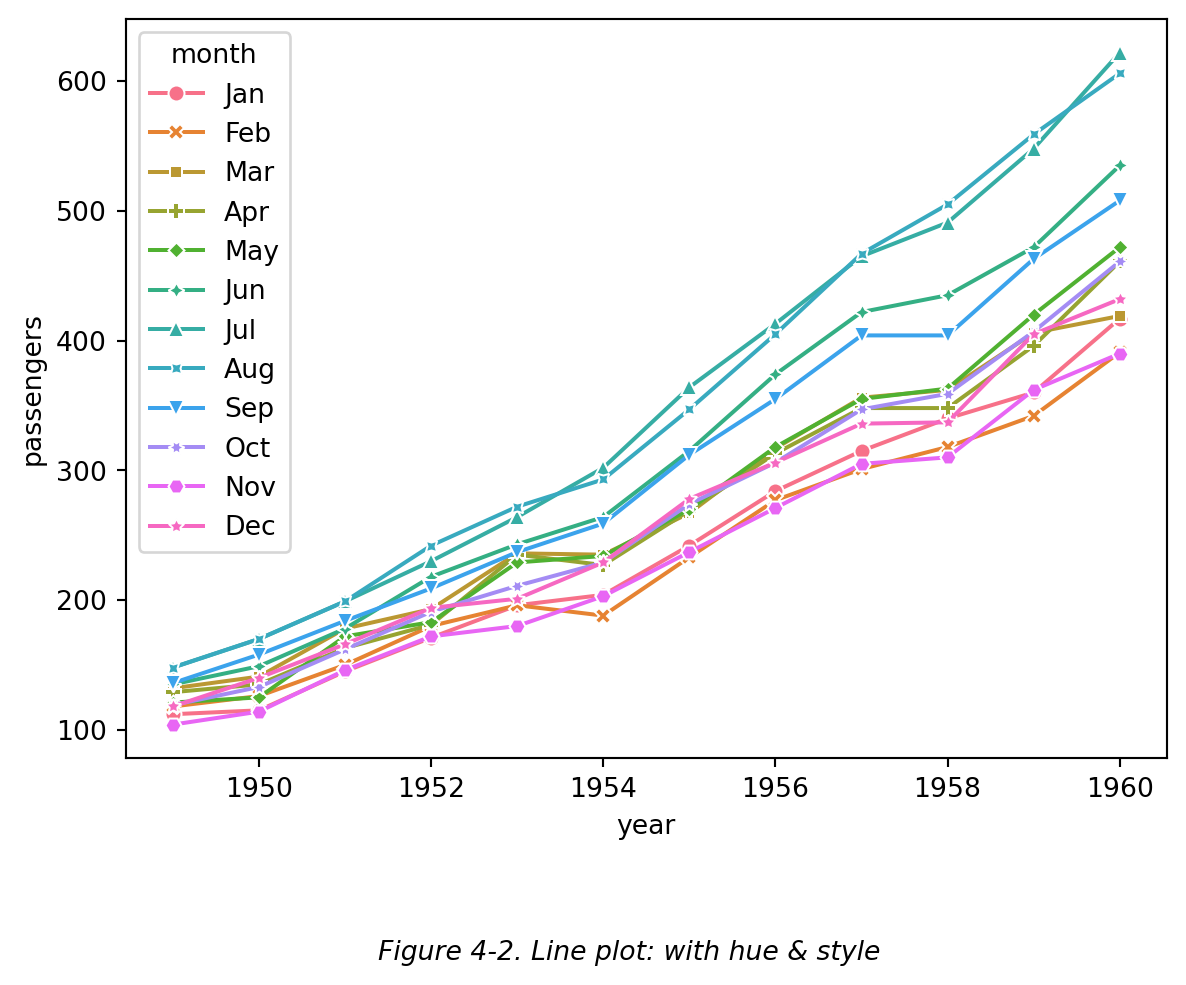
但是,当折点很多时,不建议在折线图中展示折点,过多的折点会阻碍阅读;相反,清晰的一条线更能彰显数据随时间的变化趋势 (Wilke, 2019, pp. 135-137)。
如果通过 Seaborn 绘制点图 (point plot),也可达到类似的效果,见下图 (Figure 4-3):
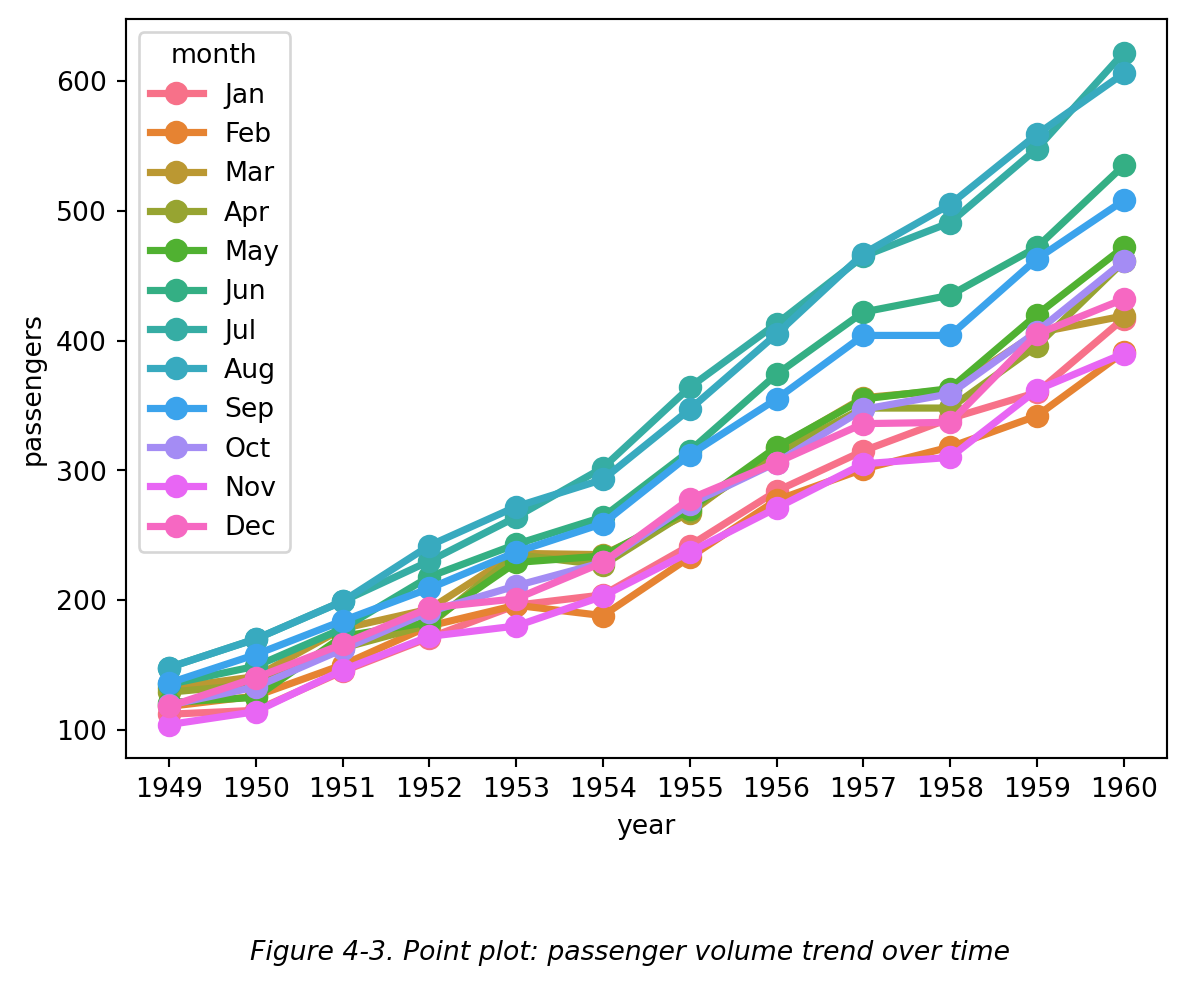
但是,sns.pointplot() 函数不可用不同点形状区分其他变量,也不可改变点大小,更不可去除点。
因此,要想观察一个变量随时间变化的趋势,最好选择 sns.lineplot() 而不是 sns.pointplot()。
此外,当 y 轴变量在每个时间点上有不止一个值,且没有用其他参数(如颜色)对其进行区分时,用 sns.lineplot() 画折线图会自动生成一条平均值折线和误差区间(默认置信水平 95%),见下图 (Figure 4-4)。
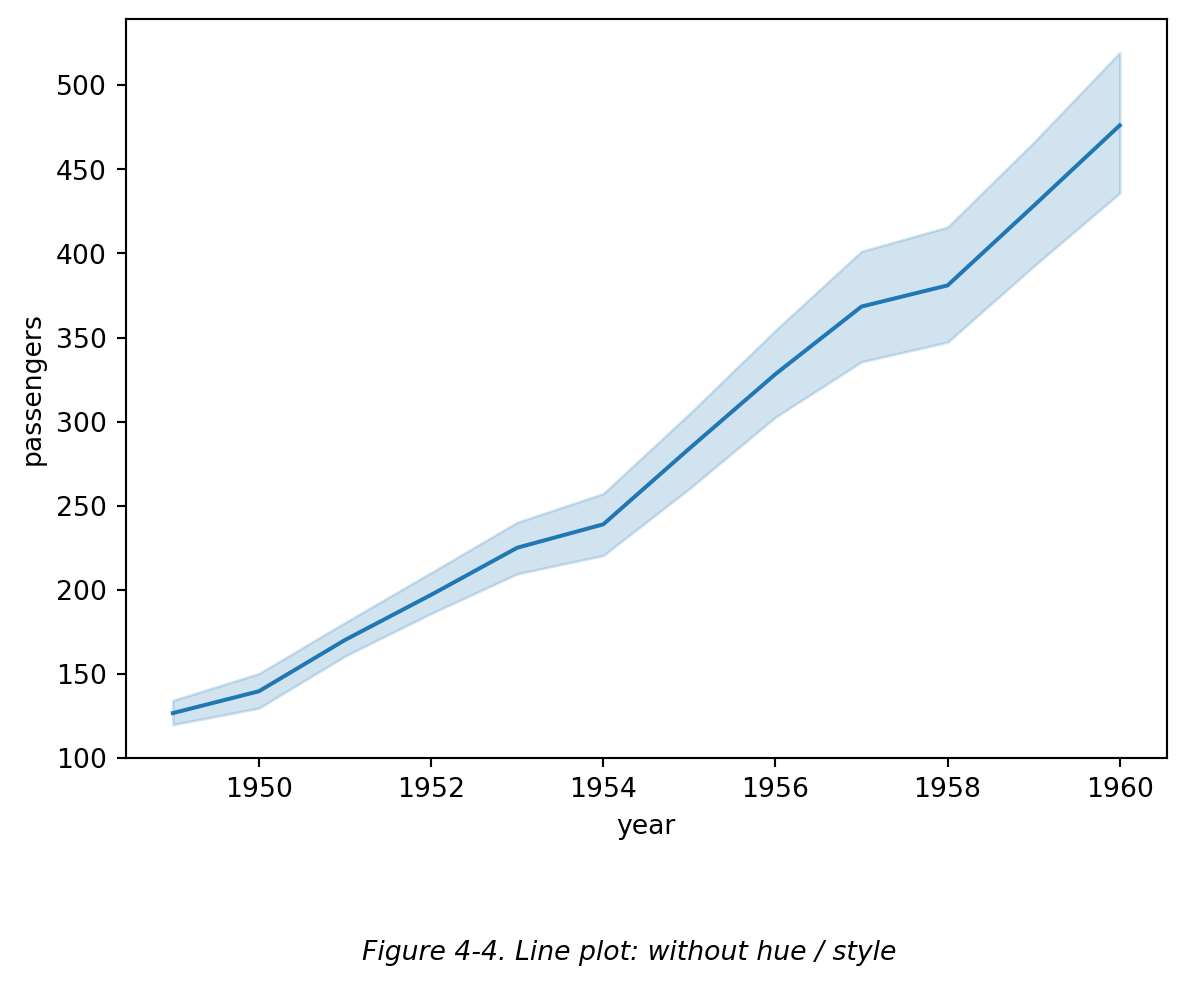
在折线图中使用颜色区分不同的线条时,需要注意:
* 图例颜色顺序应当符合线条颜色顺序
* 选择的颜色尽量兼顾患有色觉缺陷的读者
如下面的 Figure 4-5 所示,图例和线条颜色顺序不一样,会增加阅读困难,这样的图例被 Wilke (2019, p.248) 认为是差的图例。

Figure 4-5. 差图例:图例和线条颜色顺序不匹配
相反,图例和线条颜色顺序相符的折线图被 Wilke (2019, p.249) 认为是好的图表,如 Figure 4-6 所示。

Figure 4-6. 好图例:图例和线条颜色顺序匹配(且选色兼顾色觉缺陷读者)
Wilke (2019, p.250) 还展示了不同色觉缺陷模拟下的 Figure 4-6 图表,以及去除饱和度的图表,如 Figure 4-7 所示:

Figure 4-7. 不同色觉缺陷模拟 & 去饱和度下的图表(分别为:绿色弱,红色弱,蓝色弱,去除饱和度)
由 Figure 4-7 可见,Figure 4-6 中的图表使用的颜色,对于三种色觉缺陷患者而言都可以区分;并且在去除饱和度的情况下,也能通过明度不同加以区分。由于色觉缺陷患者眼中的这些颜色虽然有区别但是区别很微妙,图例和线条颜色顺序相匹配显得尤为重要。
除此之外,Wilke (2019, p.251) 还建议 进一步缩小折线图的阅读难度——去除图例,直接在折线旁标注文字。 如下图 (Figure 4-8) 所示:

Figure 4-8. 去除图例,直接在折线旁边标注文字
如 Figure 4-8,这样操作节省了读者对照图例的工作量,让图表更易读。但是这种操作通过 Seaborn 实现起来较为困难,本门课程中不必使用。用 Figure 4-6 中的符合颜色顺序的图例即可。
**
热力图 Heatmap
**
**
5.1 数据透视表 (枢轴表) Pivot Table
**
在绘制热力图之前,我们需要先给原数据创建一个 pivot table(数据透视表,又称“枢轴表”)。数据透视表将原表格中的多个 (两个) 变量以矩阵的形式展现,即,列名是一个变量,行名是另一个变量。
pivot 操作 将原表某列中的所有数据种类转变为新的列名 (column label) 或 行名/索引 (index)。如下表 (Table 5.1-2) ,把原表 (Table 5.1-1) 的 ‘year’ 列中的所有数据种类(1949~1960)变为新的列名;同理,将另一列 (‘month’) 中的所有数据种类转变为新的行名。
pivot 操作和 melt 操作相反,pivot 将 “长表格” 变为 “宽表格”,而 melt 将 “宽表格” 变为 “长表格”。melt 操作会将原本的列名变为表格内的数据值,从而让表格变得更“长”(行数更多)。
| year | month | passengers | |
|---|---|---|---|
| 0 | 1949 | Jan | 112 |
| 1 | 1949 | Feb | 118 |
| 2 | 1949 | Mar | 132 |
| 3 | 1949 | Apr | 129 |
| 4 | 1949 | May | 121 |
Table 5.1-1. 原飞行乘客表 (预览前五行)
# 创建一个数据透视表 (pivot table)
flights_pivot = pd.pivot_table(
flights, # 以 flights 表格为原数据
index='month', # 让 'month' 列中的数据种类作为新行名
columns='year', # 'year' 列中的数据种类作为新列名
values='passengers', # 'passenger' 列中的数据作为新表内部的数据
observed=False, # 显示所有分类变量的可能组合(即使有些组合在原数据中可能未出现)。
# 此处所有组合在原表中都出现了,所以新表中没有 NaN 数据。
)
# ⭕注: 由于要创建的数据透视表是一个矩阵的形式,所以也可以给变量命名为 matrix,此处命名为 flights_pivot。| year | 1949 | 1950 | 1951 | 1952 | 1953 | 1954 | 1955 | 1956 | 1957 | 1958 | 1959 | 1960 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| month | ||||||||||||
| Jan | 112.0 | 115.0 | 145.0 | 171.0 | 196.0 | 204.0 | 242.0 | 284.0 | 315.0 | 340.0 | 360.0 | 417.0 |
| Feb | 118.0 | 126.0 | 150.0 | 180.0 | 196.0 | 188.0 | 233.0 | 277.0 | 301.0 | 318.0 | 342.0 | 391.0 |
| Mar | 132.0 | 141.0 | 178.0 | 193.0 | 236.0 | 235.0 | 267.0 | 317.0 | 356.0 | 362.0 | 406.0 | 419.0 |
| Apr | 129.0 | 135.0 | 163.0 | 181.0 | 235.0 | 227.0 | 269.0 | 313.0 | 348.0 | 348.0 | 396.0 | 461.0 |
| May | 121.0 | 125.0 | 172.0 | 183.0 | 229.0 | 234.0 | 270.0 | 318.0 | 355.0 | 363.0 | 420.0 | 472.0 |
| Jun | 135.0 | 149.0 | 178.0 | 218.0 | 243.0 | 264.0 | 315.0 | 374.0 | 422.0 | 435.0 | 472.0 | 535.0 |
| Jul | 148.0 | 170.0 | 199.0 | 230.0 | 264.0 | 302.0 | 364.0 | 413.0 | 465.0 | 491.0 | 548.0 | 622.0 |
| Aug | 148.0 | 170.0 | 199.0 | 242.0 | 272.0 | 293.0 | 347.0 | 405.0 | 467.0 | 505.0 | 559.0 | 606.0 |
| Sep | 136.0 | 158.0 | 184.0 | 209.0 | 237.0 | 259.0 | 312.0 | 355.0 | 404.0 | 404.0 | 463.0 | 508.0 |
| Oct | 119.0 | 133.0 | 162.0 | 191.0 | 211.0 | 229.0 | 274.0 | 306.0 | 347.0 | 359.0 | 407.0 | 461.0 |
| Nov | 104.0 | 114.0 | 146.0 | 172.0 | 180.0 | 203.0 | 237.0 | 271.0 | 305.0 | 310.0 | 362.0 | 390.0 |
| Dec | 118.0 | 140.0 | 166.0 | 194.0 | 201.0 | 229.0 | 278.0 | 306.0 | 336.0 | 337.0 | 405.0 | 432.0 |
Table 5.1-2. 数据透视表:年 & 月 - 乘客量
注:
pd.pivot_table() 函数默认的 aggfunc 参数 (aggregation function 的缩写) 为 'mean',即,当生成的透视表中,一个单元格对应的原数据不止一组时,默认求元数据的平均值作为透视表单元格内数据。
此处 (Table 5.1-1 和 Table 5.1-2) 使用了 flights 数据表,该表中,特定 year 和 month 下,对应的 passenger 只有一个数据,所以生成数据透视表时不用求平均值。
然而,像 penguins 数据表,如下表(Table 5.1-3):
| species | island | bill_length_mm | bill_depth_mm | flipper_length_mm | body_mass_g | sex | |
|---|---|---|---|---|---|---|---|
| 0 | Adelie | Torgersen | 39.1 | 18.7 | 181.0 | 3750.0 | Male |
| 1 | Adelie | Torgersen | 39.5 | 17.4 | 186.0 | 3800.0 | Female |
| 2 | Adelie | Torgersen | 40.3 | 18.0 | 195.0 | 3250.0 | Female |
| 3 | Adelie | Torgersen | NaN | NaN | NaN | NaN | NaN |
| 4 | Adelie | Torgersen | 36.7 | 19.3 | 193.0 | 3450.0 | Female |
Table 5.1-3. 原企鹅数据表(预览前五行)
可以看出,企鹅数据表中,同一种类、同一岛屿的企鹅不止一只(即,observation 不止一行),但是它们在数据透视表 (如 Table 5.1-4) 中只对应一个单元格,因此默认求其平均值。
| island | Biscoe | Dream | Torgersen |
|---|---|---|---|
| species | |||
| Adelie | 38.975000 | 38.501786 | 38.95098 |
| Chinstrap | NaN | 48.833824 | NaN |
| Gentoo | 47.504878 | NaN | NaN |
Table 5.1-4. 数据透视表:企鹅种类 & 岛屿 - 鳍长
**
5.2 绘制热力图
**
使用 Table 5.1-2 绘制热力图,见 Figure 5.2-1:
# 用刚生成的透视表 (Table 5.1-2) 画热力图
sns.heatmap(data=flights_pivot, cbar_kws={'label':'passengers'})
#【data】
# .heatmap 直接使用矩阵形式的表格画图,而不是通过指定 x/y 参数为原 dataframe 中的特定列来画图。
#【cbar_kws】
# colorbar keyword arguments 彩色条关键字参数。此处设置了色彩条的标签。
plt.figtext(0.5,-0.1,"Figure 5.2-1. Heatmap: flights",ha="center",fontsize=10,style='italic')
plt.show()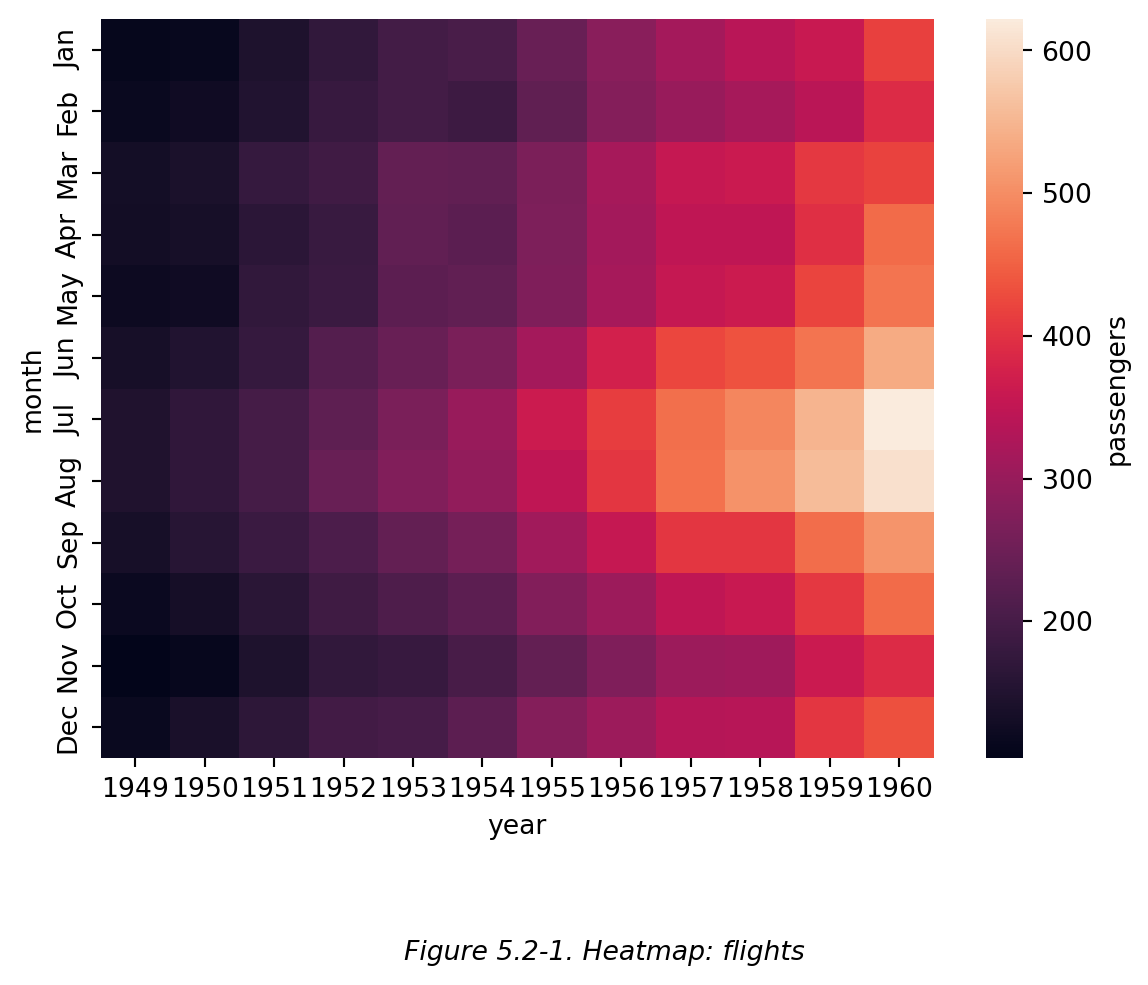
还可以通过设置 sns.heatmap() 函数中的 其他参数(如:cmap,annot)来进一步修改热力图,如下图(Figure 5.2-2):
# 设置热力图的其他参数
sns.heatmap(
data=flights_pivot, cbar_kws={'label':'passengers'},
cmap='viridis', # 更改使用的 colormap(Matplotlib 中预制的 colormap)
annot=True, # annotation,给热力图格子添加注释,显示 data 使用的表格中的数据
fmt = '.0f', # format,和 annot 联用。'.nf'是用于更改浮点数格式的代码,
# 意为 “保留到第n位小数”,此处 n=0,即为保留整数。
)
#【cmap】
# colormap。设置热力图使用的颜色图 (colormap)。
# 可以使用 Seaborn 或 Matplotlib 中预制的 color palette 或 colormap 名称,
# 如:'crest','flare', 'viridsis','pink' 等。
plt.figtext(0.5,-0.1,"Figure 5.2-2. Heatmap: flights (added more arguments)",
ha="center",fontsize=10,style='italic')
plt.show()
同理,也可以使用 Table 5.1-4 绘制热力图,见下图 (Figure 5.2-3):
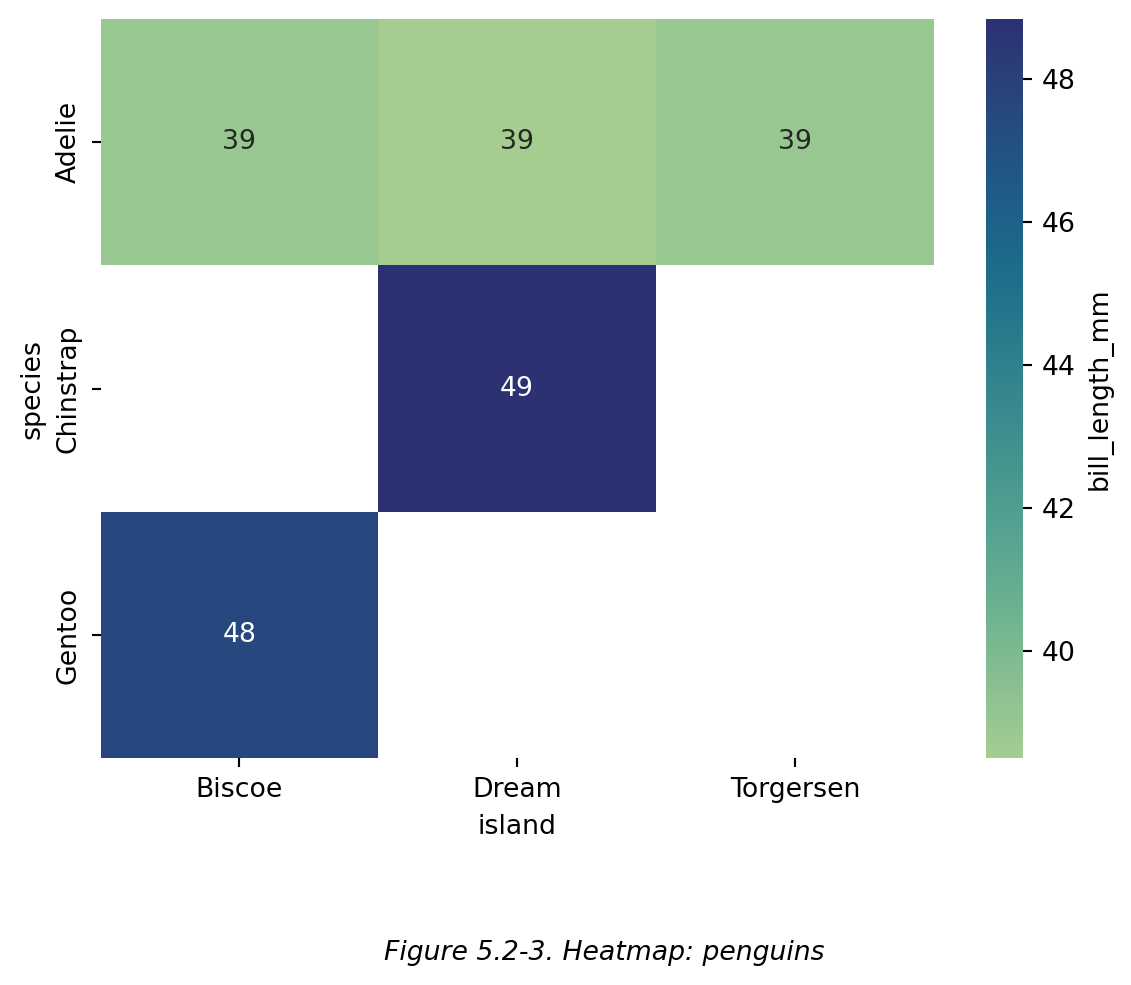
**
二维直方图 2-dimensional histogram
**
根据 Wilke (2019, pp. 222-225) 介绍,我们可以使用含有半透明点的散点图展示数据在两个变量控制下的分布情况,然而如果数据点过多、过密,就会导致散点图难以展示整体数据分布。如下图 (Figure 6-1) 点密度高的区域将显示为深色的均匀斑点,而在点密度低的区域中,各个点几乎不可见。

Figure 6-1. 数据点过多、过密的散点图 (Wilke, 2019, p. 223)
此时,我们可以改用 二维直方图/2D直方图 (2-dimenl histogram),而不是绘制单个点(散点图)。二维直方图将整个 x - y 平面细分为小矩形,每个矩形是一个分箱 (bin),并计算落入每个分箱的数据量,然后按照数据量的大小对矩形进行着色。如下图 (Figure 6-2):
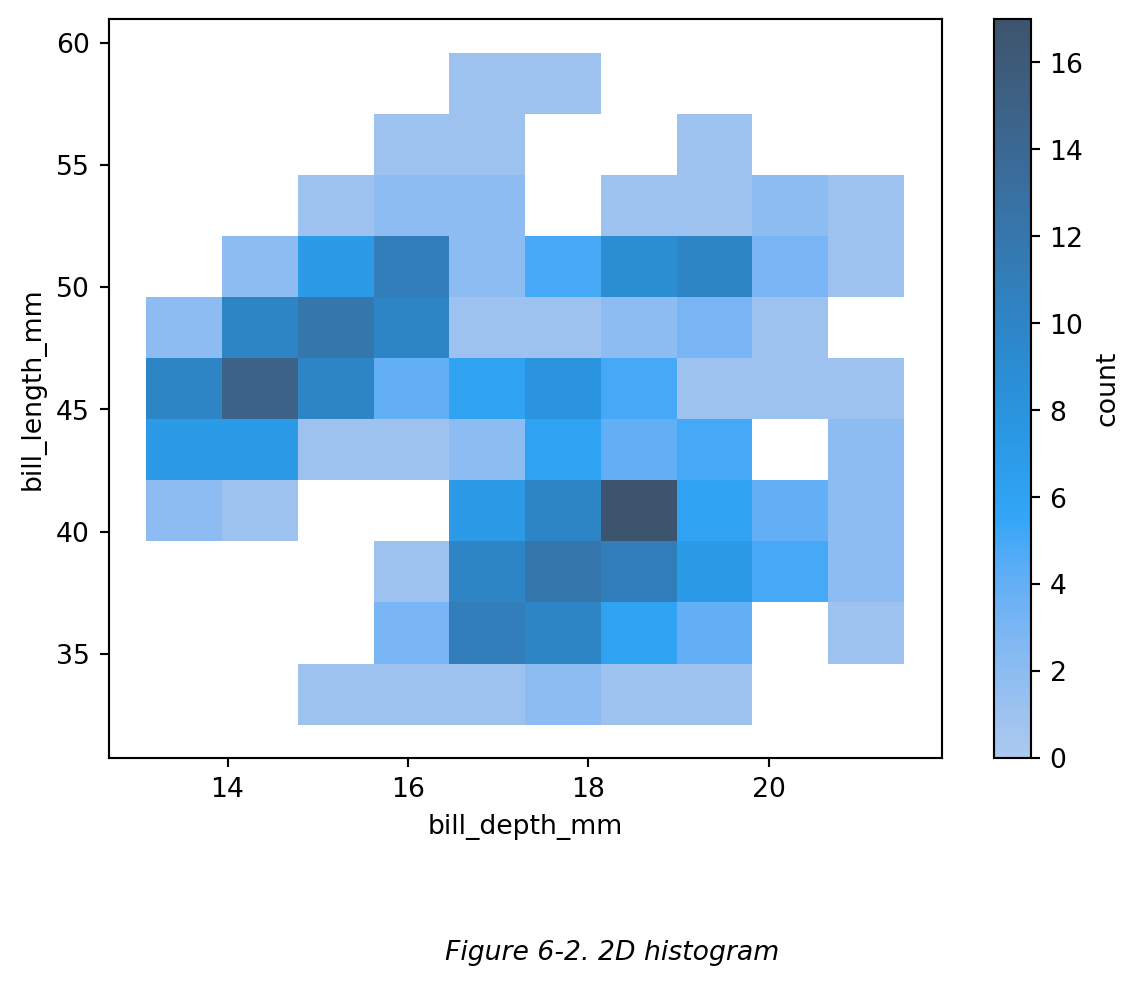
下表 (Table 6-1) 展示了热力图和二维直方图的区别:

Table 6-1. 热力图和二维直方图的区别
**
双变量图 Joint Plot
**
利用 Seaborn 的 sns.jointplot() 函数,我们可以画一个双变量图,同时展示包含两个变量的二元分布图,和这两个变量各自的一元分布图。
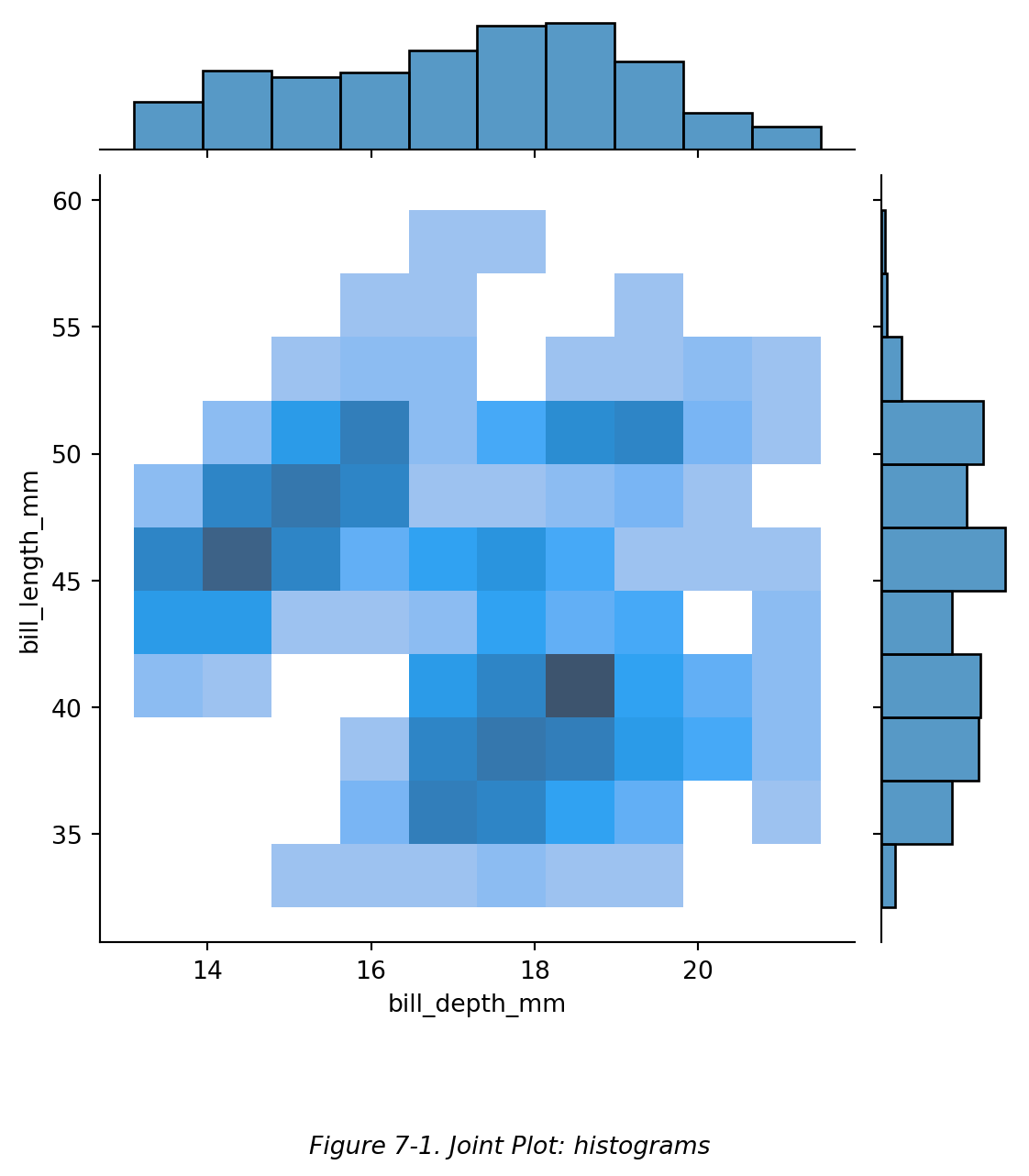
如下图 (Figure 7-1),我们可以在展示二维直方图 (同 Figure 6-2) 的同时,展示两个变量各自的一维直方图。
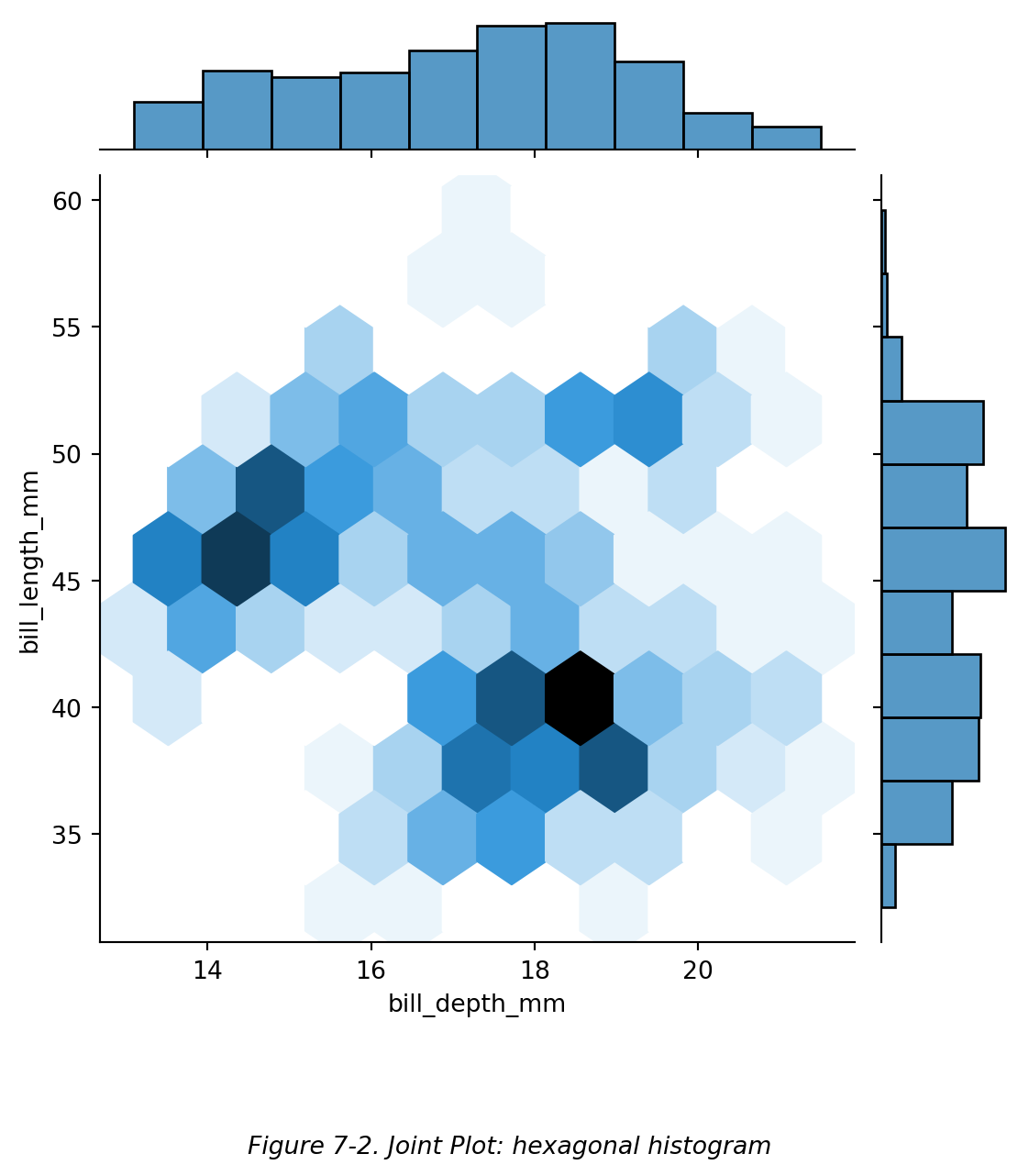
还可以通过控制参数 kind='hex' 来让中间的各自呈六边形,如下图 (Figure 7-2):
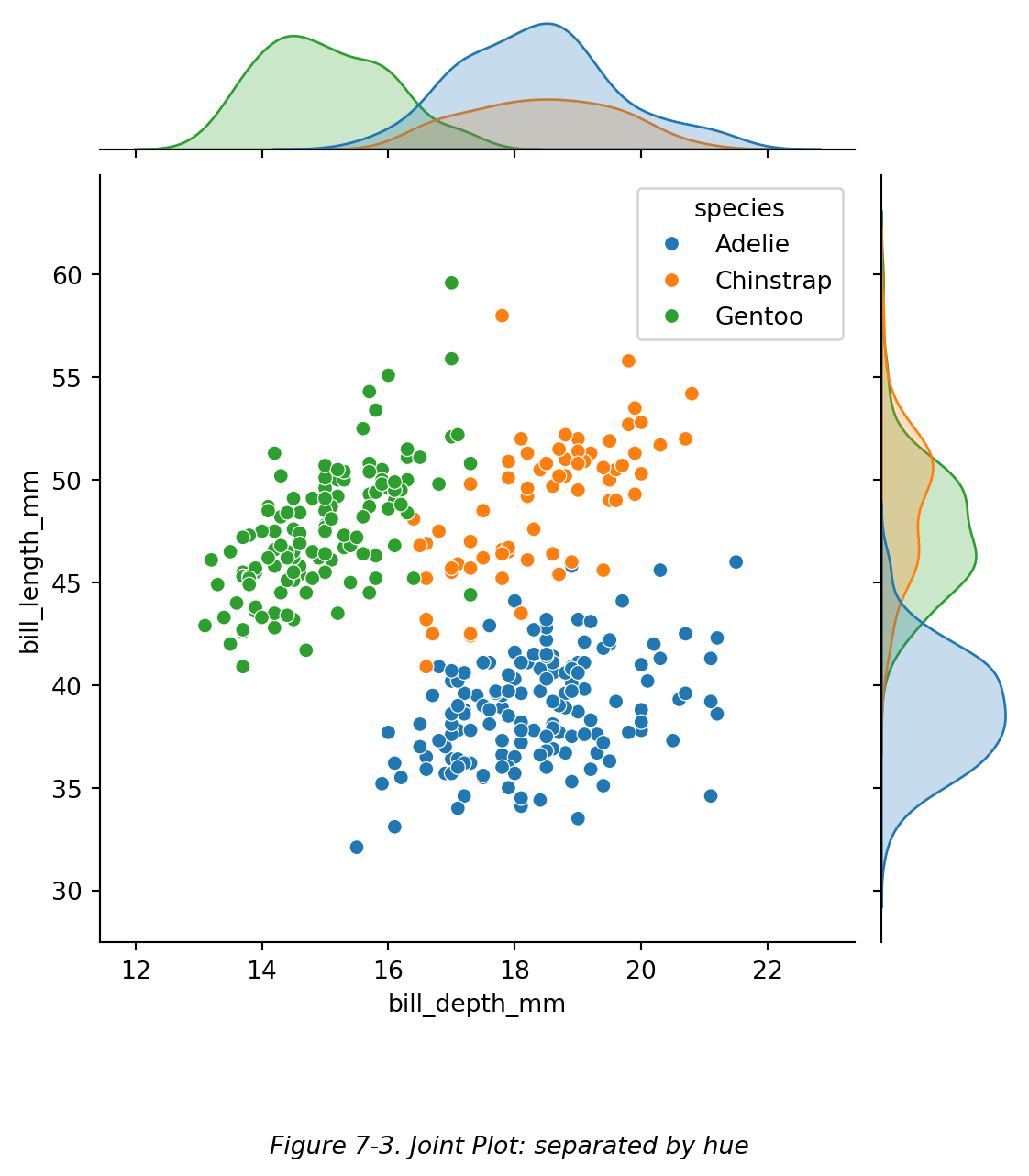
还可以展示其他形式的分布图,如下图 (Figure 7-3):
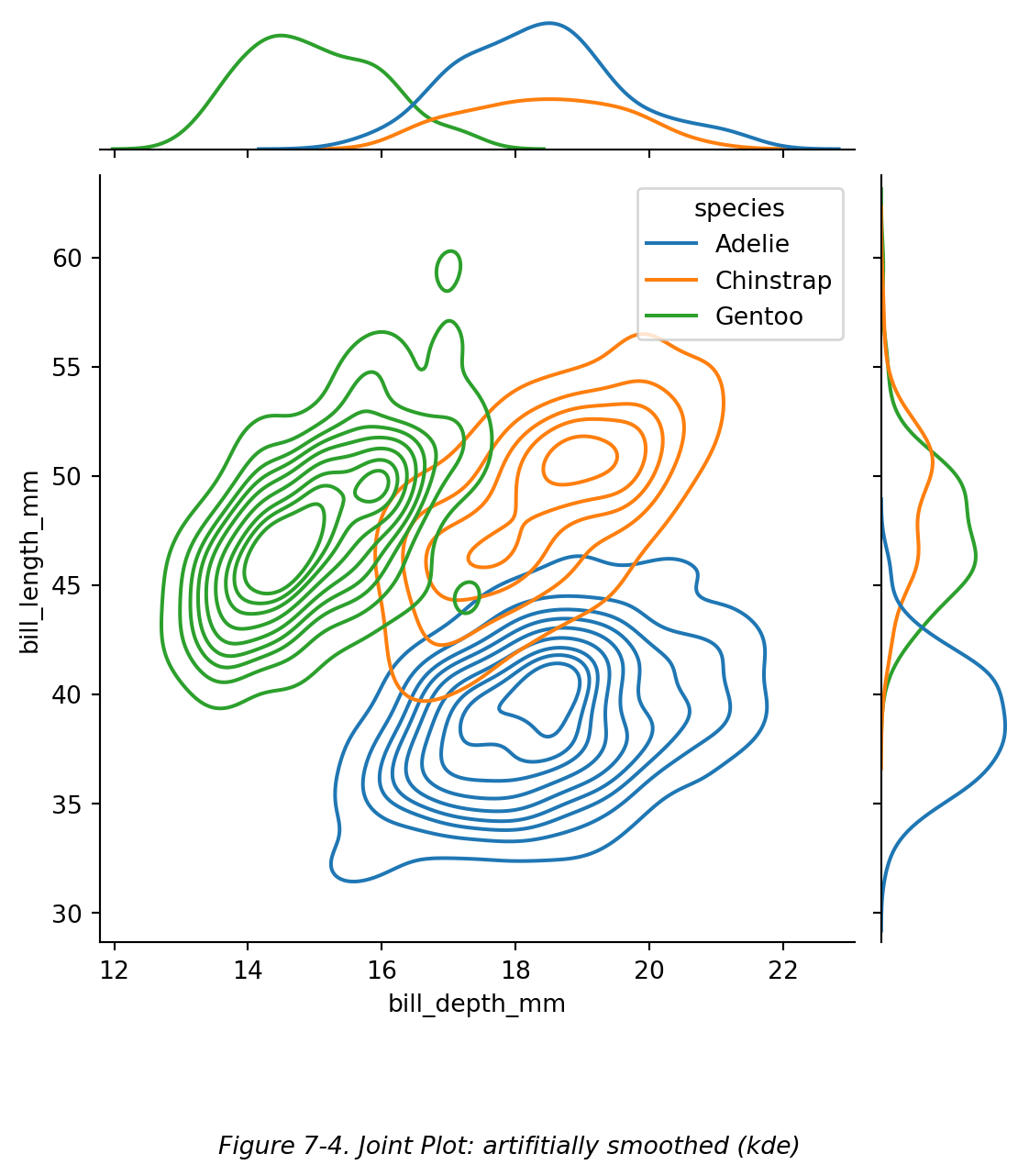
还可以通过设置参数 kind='kde' (abbr. ‘kernal density estimation’) 来生成自动光滑化的分布曲线,如下图 (Figure 7-4)。但是由于光滑化后的曲线并非真实数据,可能会误导读者,尤其是当数据点量非常少的时候。因此不建议在本课程中使用。
**
配对图 Pair Plot
**
使用 Seaborn 的 sns.pairplot() 函数可以轻松画出原数据表中多个变量(即,原数据表中的多列)各自两两配对的分布图表,进而形成一个图表阵。如下图(Figure 7-4):
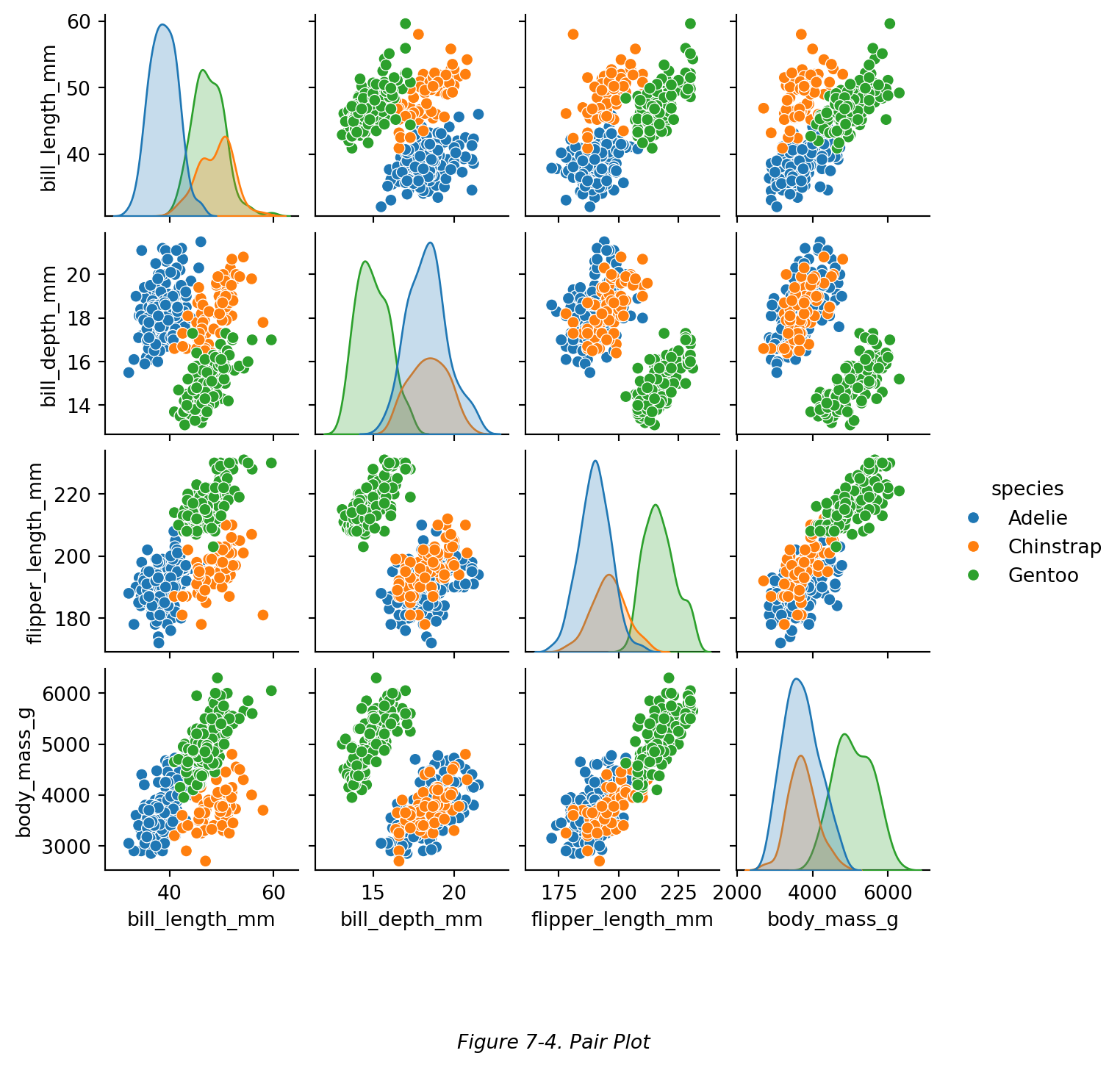
Figure 7-4 中,原 DataFrame 中的四个 ratio 变量(列)被自动识别,并作为数据画图。其中对角线的图是这四个变量各自的一元分布图,而除此之外的每个子图表都是基于一对变量(两个变量)绘制出的二元分布图。
同理,我们可以通过设置参数 diag_kind 和 kind 来修改对角线图表和其他二元图表的格式,如下图 (Figure 7-4)。
# 加入两句 keyword arguments
sns.pairplot(
data=df,
hue='species',
diag_kind='hist', # kind of plot for the diagonal subplots 对角线图表的形式
kind='hist', # 每个二元分布图的形式(即,除了对角线之外的所有图表)
height=1.7 # 调整图片大小
)
plt.figtext(0.5,-0.1,"Figure 7-4. Pair Plot: histograms",ha="center",fontsize=10,style='italic')
plt.show()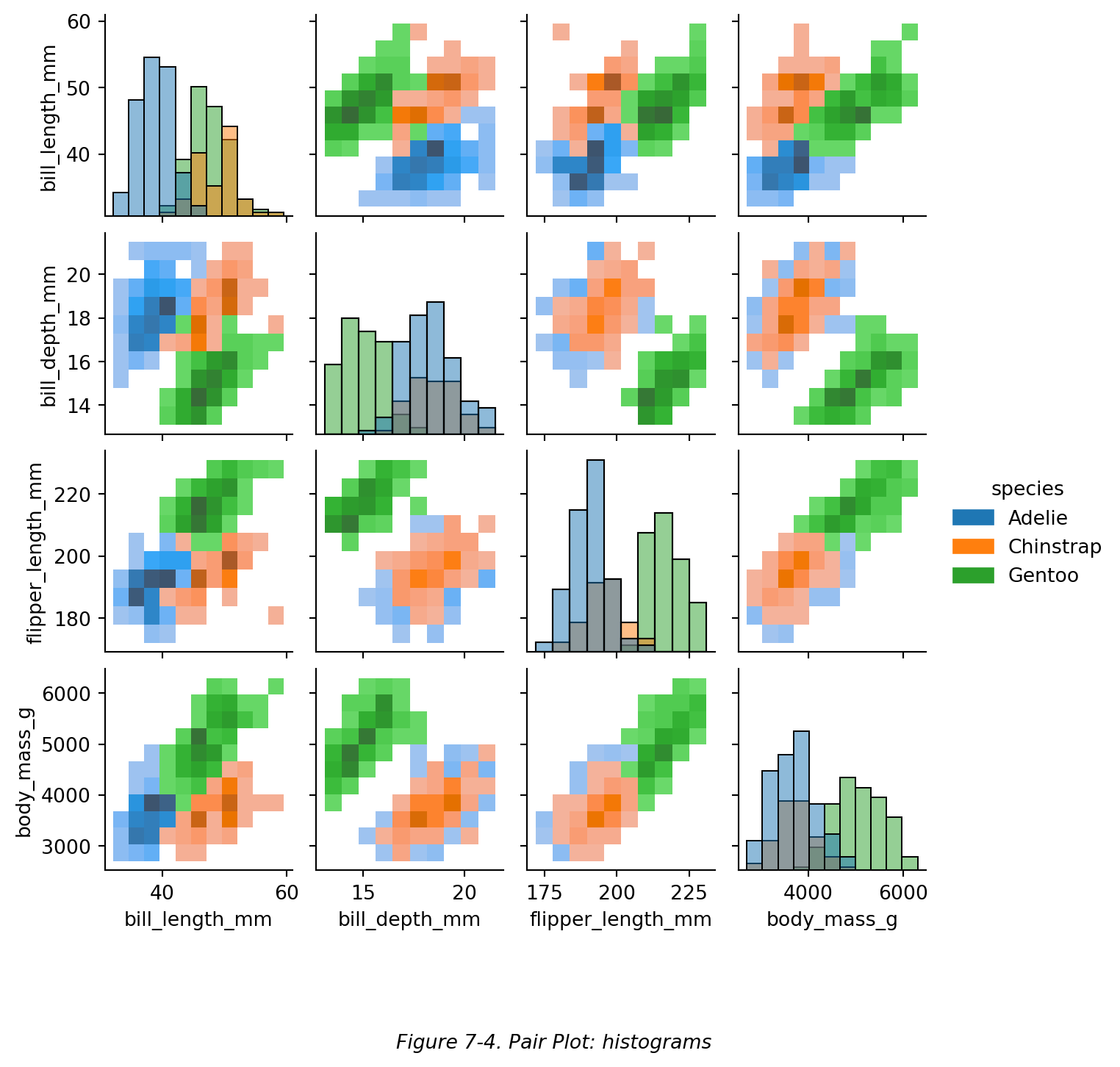
---
title: '**W05 多变量图表 Multivariate Plots**'
jupyter: python3
---
# **目录**
> <a href="#1-多变量数据-multivariate-data"> 1. 多变量数据 Multivariate Data </a>
>
> <a href="#2-分面网格-facetgrid"> 2. 分面网格 Facetgrid </a>
>
> <a href="#3-散点图-scatter-plot"> 3. 散点图 Scatter Plot </a>
>
> > <a href="#3.1-区分散点图-scatter-plot-和点图-point-plot"> 3.1 区分散点图 (scatter plot) 和 点图 (point plot) </a>
> >
> > <a href="#3.2-多变量散点图-multivariate-scatter-plot"> 3.2 多变量散点图 Multivariate Scatter Plot </a>
> >
> > <a href="#3.3-对数尺度-logarithmic-scales"> 3.3 对数尺度 Logarithmic Scale </a>
> >
> > <a href="#3.4-回归图-regression-plot"> 3.4 回归图 Regression Plot </a>
>
> <a href="#4-折线图-line-plot"> 4. 折线图 Line Plot </a>
>
> <a href="#5-热力图-heatmap"> 5. 热力图 Heatmap </a>
>
> > <a href="#5.1-数据透视表-枢轴表-pivot-table"> 5.1 数据透视表 (枢轴表) Pivot Plot </a>
> >
> > <a href="#5.2-绘制热力图"> 5.2 绘制热力图 </a>
>
> <a href="#6-二维直方图-2-dimensional-histogram"> 6. 二维直方图 2-dimensional histogram </a>
>
> <a href="#7-双变量图-joint-plot"> 7. 双变量图 Joint Plot </a>
>
> <a href="#8-配对图-pair-plot"> 8. 配对图 Pair plot </a>
\*\*
<h1 id="1-多变量数据-multivariate-data">
1. 多变量数据 Multivariate Data
</h1>
\*\*
本门课涉及的表格都是 *tidy* 、 *flat* 的表格。即, 每行 为一个 *observation* (或 *instance*\*\* 或 *record* ) ,而 [**每列**]{style="color:FireBrick"} 为一个 *attribute* 或 [*variable* (变量)]{style="color:FireBrick"} 或 ***feature*** 或 ***parameter*** (参数) 。针对不同情况,可能使用不同的术语来称呼行和列。
通常,***multivariate*** (多元的、多变量的) 用于描述 ***variable*** 超过两个的数据。[**即,multivariate plot 通常使用了原 DataFrame 中三个或三个以上的列作为数据。**]{style="color:FireBrick"}
根据之前学过的柱状图画法,除了 x, y 两个变量之外,我们还可以设置 `hue` 参数 ,从而实现绘制一个包含三个变量的柱状图。比如下图 Figure 1-1 中包含了 `'island'` , `'bogy_mass_g'` , `'sex'` 三个列的数据,即,三个变量的数据。
```{python}
# 导入库 | import libraries
import pandas as pd # 用于处理 DataFrame
import seaborn as sns # 用于快速画图表
import matplotlib.pyplot as plt # 用于处理和展示图表
```
```{python}
# 从 Seaborn 库中加载一个示例数据集 | load a sample dataset from Seaborn
df = sns.load_dataset('penguins')
```
```{python}
# 绘制包含三个变量的柱状图
sns.barplot(df,x='island',y='body_mass_g',hue='sex')
plt.figtext(0.5,-0.1,
"Figure 1-1. Bar plot: 3 variables",
ha="center",fontsize=10,style='italic', # 给图片添加编号和注释,下同。
)
plt.show()
```
然而,有的图表类型不支持同时设置 `x` , `y` 和 `hue` 参数 来展示三个变量。比如直方图中,只支持 `x` 和 `hue` 参数的设置,见 Figure 1-2。直方图中 x 轴 和 y 轴展示的都是 'flipper_length_mm' (鳍长)这个变量,x轴 展示的是鳍长的分布区间,y轴 展示的在鳍长的每个区间内,企鹅的量。因此这个直方图中只有两个变量(即原 dataframe 中的两个列)。
```{python}
# 绘制直方图
sns.histplot(data=df,x='flipper_length_mm',hue='island')
plt.figtext(0.5,-0.1,"Figure 1-2. Histogram: 2 variables",ha="center",fontsize=10,style='italic')
plt.show()
```
\*\*
<h1 id="2-分面网格-facetgrid">
2. 分面网格 Facetgrid
</h1>
\*\*
分面网格(facetgrid)是展示多元变量的一个常用方法。在一个分面网格中,若干个小图表将作为子图表,成网格状排列。一个子图表被称为一个分面 (facet),所有分面组成了一个分面网格 (facetgrid)。如果我们既想要展示直方图,又想要展示两个以上的变量,可以使用分面网格。
通过 Seaborn 绘制分面网格的方法如下:
```{python}
# 创建分面网格 (facetgrid)
g = sns.FacetGrid(
data=df,
col='sex', # col: 设置网格的列。df 中'sex'列的数据有多少种,生成的网格就有多少列。
row='island', # row: 设置网格的行。同上,df 中一共有三个岛,所以生成的网格有三行。
)
# g: grid 网格
#【FacetGrid】
# FacetGrid 是由多个小图表组成的网格。
# 如下 (Figure 2-1) 是一个 3x2 (三行两列) 的 分面网格 (facetgrid)。
plt.figtext(0.5,-0.1,"Figure 2-1. Empty facetgrid",ha="center",fontsize=10,style='italic')
plt.show()
```
如 Figure 2-1,通过定义 `g = sns.FacetGrid(data=df,col='sex',row='island')` ,我们创建了一个包含许多小图表的网格。
但是此时只创建了网格,还需要通过 `.map_dataframe()` 方法来指定具体填充内容。
```{python}
# 绘制完整的分面网格图
#【第一步】
# 创建分面网格
g = sns.FacetGrid(
data=df,
col='sex',
row='island',
hue='species', # 使用不同颜色来区分不同种类的企鹅
)
#【第二步】
# 指定要填充的内容
g.map_dataframe(
sns.histplot, # 画图要使用的函数,此处使用 sns.histplot 函数绘制直方图
x='flipper_length_mm', # 指定直方图中的 x 轴数据为鳍长
stat='density',
common_norm=False,
)
#【stat = 'density'】
# 用频率密度统计方法绘图,使直方图内所有 bar 的面积之和为 1。
#【common_norm = False】
# 配合 stat 参数使用。此处 False 意为: 在同一个小直方图中 (在一个分面中),
# 每种颜色的 bar 面积之和分别为 1,而非所有颜色的 bar 面积总和为 1
#【第三步】
# 添加并调整图例
g.add_legend() # 添加图例
sns.move_legend( # 调整图例
g,
loc='lower center',
bbox_to_anchor=(0.5,1),
ncol=3,
)
#【loc & bbox_to_anchor】
# 同时设置两个参数,让图例的下边缘中点 (lower center) 位于整个网格图的 (0.5,1) 位置
# 注:如果只设置了 loc = 'lower center',而没设置 bbox_to_anchor 参数的话,
# 图例将直接根据 loc 参数的值 'lower center' 定位于整个网格图的中下部。
#【ncol】
# number of columns:图例的列数
plt.figtext(0.5,-0.1,"Figure 2-2. Filled facetgrid",ha="center",fontsize=10,style='italic')
plt.show()
```
如 Figure 2-2,我们创建了一个分面网格,包含根据 ***鳍长*** 范围区间不同绘制了若干直方图,且按照 ***岛屿*** 不同进行了分行,按照 ***性别*** 不同进行了分列,按照 ***种类*** 不同进行了分色。由此可见,通过分行和分列,我们可以额外增加两个离散型变量;同时,通过区分颜色,可以再增加一个离散型变量。
> [*注:由于分行和分列的特性,分面网格只能用于额外增加离散型变量。但可以给连续型变量划分区间,然后把不同区间范围保存为一个新的离散型变量(即,在 dataframe 中新增加一列),再用分面网格进行分行或分列。*]{style="color:FireBrick"}
此外,同时绘制多个小图表排列在一起展示(比如分面网格)时,需要注意 [**每个子表格的刻度范围应当相同**]{style="color:FireBrick"}。因为展示多图时,读者往往会默认它们的刻度范围是相同的;如果不相同,可能会造成误判,增加阅读困难 (Wilke, 2019, pp. 257-258)。
如下图 (Figure 2-3),每个小图表的纵坐标刻度范围各不相同,容易让人误判。

*Figure 2-3. 差的多图刻度范围 (Wilke, 2019, p. 258)*
将 Figure 2-3 中的图改成下图 (Figure 2-4) 这样所有刻度范围都相同,可以减少读者阅读困难。

*Figure 2-4. 改良版多图刻度范围 (Wilke, 2019, p. 259)*
\*\*
<h1 id="3-散点图-scatter-plot">
3. 散点图 Scatter Plot
</h1>
\*\*
\*\*
<h2 id="3.1-区分散点图-scatter-plot-和点图-point-plot">
3.1 区分散点图 (scatter plot) 和 点图 (point plot)
</h2>
\*\*
在画散点图 (scatter plot) 之前,需要注意区分 **散点图 (scatter plot)** 和 **点图 (point plot)** 。\
\>\*
<p style="color:FireBrick">
注:点图又称 dot plot (Wilke, 2019, p.43)。以下所有对于散点图与点图的区别的理解均基于 Seaborn 库,在其他语境下可能有所不同。
</p>
-
**点图 (point plot)** 可以起到类似柱状图或直方图的作用。点图每个点所在的竖线相当于柱状图的 bar 或直方图的 bin,而点图中的点则相当于柱状图中每个 bar 的顶边缘中点。像柱状图一样,点图可以用于展示 category-amount 型图表,比如下面两图 (Figure 3.1-1 和 Figure 3.1-2):
```{python}
# 点图 (point plot) 示例:企鹅种类-喙长 category-amount
sns.pointplot(data=df, x='species',y='bill_length_mm',
linestyles='none') # 让点与点之间不要连线
# 绘制不同种类企鹅的鳍长平均值点图。比如所有 Adelie 企鹅的喙长平均值约为 39。Figure 3.1-1 中的竖线为误差线。
plt.figtext(0.5,-0.1,"Figure 3.1-1. Point plot: category-amount",ha="center",fontsize=10,style='italic')
plt.show()
```
```{python}
# 柱状图示例:企鹅种类-喙长 category-amount
sns.barplot(data=df, x='species',y='bill_length_mm')
# 绘制不同种类企鹅的鳍长平均值柱状图。点图中的点相当于柱状图中的柱子上边缘中点。Figure 3.1-2 中黑线是误差线。
plt.figtext(0.5,-0.1,"Figure 3.1-2. Bar plot: category-amount",ha="center",fontsize=10,style='italic')
plt.show()
```
如上面两图 (Figure 3.1-1 和 Figure 3.1-2) 所示,**点图 (point plot)** 和 **柱状图** 都可以表示企鹅 企鹅种类-喙长 的关系,其中企鹅种类是 categorical data,而喙长是 numerical data,即 category-amount 的关系。这两种图的区别之一是,柱状图的 amount 必须从 0 开始,点图不需要从 0 开始。
需要注意的是,**点图 (point plot)** 和 **柱状图** 都只展示纵坐标的平均值(也可以自己设置为其他值,比如中位数)。因为在这两种图中,一个横坐标值只能对应一个纵坐标值。即,每个种类的企鹅只对应了一个显示其平均喙长的点/柱。
而 **散点图 (scatter plot)** 会显示每一个数据点。比如下面的图 (Figure 3.1-3):
```{python}
# 散点图示例:企鹅种类-喙长 category-amount
sns.scatterplot(data=df, x='species',y='bill_length_mm')
# 和 Figure 3.1-1 中的点图 (point plot) 不同,Figure 3.1-3 中散点图 (scatter plot) 显示出所有的数据点。
plt.figtext(0.5,-0.1,"Figure 3.1-3. Scatter plot: category-amount",ha="center",fontsize=10,style='italic')
plt.show()
```
\*\*
<p style="color:FireBrick">
散点图 (scatter plot) 中每个横坐标可以对应许多纵坐标,而点图 (point plot) 中每个横坐标只能对应一个纵坐标。
</p>
\*\*
此外,**散点图 (scatter plot)** 常用于探究两个(或多个)变量之间的关系 (relationship),查看变量间是否存在关联性 (correlation),最终可以用于分析二者间是否存在因果关系 (causation),主要用于探究两种连续的数值型数据之间的关系。因此,散点图横轴使用的数据通常为 ratio data,画图时横轴刻度会自动显示为连续的数值区间,比如 Figure 3.1-4:
```{python}
# 散点图示例:企鹅喙长-喙深 ratio-ratio
sns.scatterplot(data=df,x='bill_length_mm',y='bill_depth_mm',alpha=0.7)
#【alpha】点透明度,填 0~1 的数字,1 是不透明,0 是全透明。
# ⭕注意:设置半透明的点可以帮助我们观察点的堆积,但是如果已经设置了按照渐变颜色区分某变量
# (如后文的 Figure 3.2-2),就不宜再使用半透明的点。
plt.figtext(0.5,-0.1,"Figure 3.1-4. Scatter plot: ratio-ratio",ha="center",fontsize=10,style='italic')
plt.show()
```
而画 **点图 (point plot)** 时,每一个点都会自动对应一个特定的横轴刻度,如果点图的横轴使用 ratio data,可能会产生如下效果 (Figure 3.1-5):
```{python}
# 点图示例:企鹅喙长-喙深 ratio-ratio
sns.pointplot(data=df,x='bill_length_mm',y='bill_depth_mm',linestyle='none',errorbar=None,alpha=0.7)
# ⭕注:虽然 Figure 3.1-4 和 Figure 3.1-5 中点的分布看似很相似,但 Figure 3.1-5 中每个点
# 所在的横坐标有且仅有一个对应的点,Figure 3.1-4 的横坐标则可以对应多个点。此外,sns.pointplot()
# 函数不支持调整点的大小,而 sns.scatterplot() 函数支持。
plt.figtext(0.5,-0.1,"Figure 3.1-5. Point plot: ratio-ratio",ha="center",fontsize=10,style='italic')
plt.show()
```
因此,**点图 (point plot)** [**不适用**]{style="color:FireBrick"} 于展示 **横坐标为连续型数据,且横坐标值过多** 的数据,而更 [**适用于**]{style="color:FireBrick"} 展示 **横坐标为离散型数据** 的数据,**且横坐标刻度不宜过多**。\
**散点图 (scatter plot)** 则相反,更适用于 ratio-ratio 数据的展示,即,横纵坐标都是连续型数值数据。
点图 (point plot) 的另一个特点是点与点之间可以连线,适用于横轴为 ordinal 或 interval data 数据的展示。因为当横轴刻度的顺序有意义时,连线才有讨论价值。比如下图 (Figure 3.1-6) 的年份即为 interval data,年份逐渐增加,连线可以表示年平均乘客量遂年份增加的变化趋势;而上面 Figure 3.1-1 中的点图的横坐标为企鹅种类,是 norminal data,其顺序没有意义,因此没有画连线。
而这种点图,变得和折线图非常非常类似。我们将在后续章节 <a href="#4-折线图-line-plot">4. 折线图 Line Plot</a> 中继续讨论。
```{python}
# 点图其他应用场合示例:年份-乘客数 interval-ratio
flights=sns.load_dataset('flights') # Seaborn 示例数据集 - 飞机乘客量
sns.pointplot(data=flights,x='year',y='passengers')
plt.figtext(0.5,-0.1,"Figure 3.1-6. Point plot: interval-ratio",ha="center",fontsize=10,style='italic')
plt.show()
```
\*\*
<h2 id="3.2-多变量散点图-multivariate-scatter-plot">
3.2 多变量散点图 Multivariate Scatter Plot
</h2>
\*\*
除了散点图的 x , y 轴展示的两种连续变量之间的关系之外,我们还可以通过设置 `hue` (点颜色),`size` (点大小),`style` (点形状) 等 参数,来给散点图设置其他变量。
\*\*
<p style="color:FireBrick">
以上这三个参数都可以应用于离散型变量,然而其中只有 *hue* 和 *size* 可以应用于连续型变量,因为点颜色和大小都可以连续渐变,点形状却不可以(仅限 Seaborn 库中)。
</p>
\*\*
比如下图 (Figure 3.2-1):
```{python}
# 增加离散变量:hue & size & style
ax = sns.scatterplot(
data=df,x='bill_length_mm',y='bill_depth_mm', # 散点图:企鹅喙长-喙深
hue='sex', # 用颜色区分企鹅性别
size='island', # 用点大小区分企鹅所在岛屿
style='species', # 用点形状区分企鹅种类
)
sns.move_legend(ax,loc='upper left',bbox_to_anchor=(1,1)) # 移动图例
plt.figtext(0.5,-0.1,"Figure 3.2-1. Adding discrete variables: hue & size & style",
ha="center",fontsize=10,style='italic')
plt.show()
```
Figure 3.2-1 中,除了横纵轴使用了两个连续变量(喙长 和 喙深)之外,还设置了三个离散变量(性别、岛屿 和 种类)。
再比如下图 (Figure 3.2-2):
```{python}
# 增加连续变量:hue & size
ax = sns.scatterplot(
data=df,x='bill_length_mm',y='bill_depth_mm', # 散点图:企鹅喙长-喙深
hue='flipper_length_mm',
size='body_mass_g', # 用点大小区分企鹅体质量
)
#【⭕注意】
# 如上文的 Figure 3.1-4 的代码块中提及,像本图 (Figure 3.2-2),
# 已经设置了按照渐变颜色区分鳍长,则不宜再使用半透明的点,因为透明度会影响颜色的展示。
sns.move_legend(ax,loc='upper left',bbox_to_anchor=(1,1)) # 移动图例
plt.figtext(0.5,-0.1,"Figure 3.2-2. Adding continuous variables: hue & size",
ha="center",fontsize=10,style='italic')
plt.show()
```
Figure 3.2-2 中,除了横纵轴使用了两个连续变量(喙长 和 喙深)之外,还设置了两个连续变量(鳍长 和 体质量)。
> [*注:虽然 hue 和 size 可以应用于 ratio data 列(即,可以应用于连续变量),但是其图例并非严格连续的。*]{style="color:FireBrick"}
[**总地来说,和分面网格相比,多变量散点图的优点有:**]{style="color:FireBrick"}
- **全局视图。**\
可以在同一坐标系内呈现所有数据点和变量。\
- **占用图形空间少。**\
不需要像分面网格那样创建多个子图,仅需要一个表格即可展现多个变量。\
- **可以直接增加连续变量。**\
多变量散点图可以直接增加连续型变量,并自动按区间生成图例。而分面网格需要手动设置区间范围并保存为新的变量,再画分面网格。
[**然而,多变量散点图也存在局限性:**]{style="color:FireBrick"}
- **视觉复杂。**\
所有信息都在同一张图表内展示,信息过多可能导致阅读困难。
- **依赖图例。**\
读者需要反复对照图例来看图,增加阅读困难。
- **图例难以分辨。**\
点大小和颜色可能难以分辨。
在多变量散点图中,对点大小的区分非常微妙,读者难以辨认;而对颜色的区分,也可能令读者难以辨认 (比如 浅绿色 和 绿色 ),尤其是患有色觉缺陷的读者。
因此,为了让散点图更易懂,我们可以 **同时使用颜色和形状区分一个变量** (Wilke, 2019, pp.243-247)。比如下图 (Figure 3.2-3):
```{python}
# 同时使用 hue 和 style 控制 岛屿 变量
ax = sns.scatterplot(
data=df,x='bill_length_mm',y='bill_depth_mm', # 散点图:企鹅喙长-喙深
hue='island',
style='island',
)
sns.move_legend(ax,loc='upper left',bbox_to_anchor=(1,1)) # 移动图例
plt.figtext(0.5,-0.1,"Figure 3.2-3. Hue & style: controlling the same variable 'island'",
ha="center",fontsize=10,style='italic')
plt.show()
```
如 Figure 3.2-3 所示,同时用点颜色和点形状对于岛屿进行了区分,有助于读者理解。
此外, **尽量不要在同一个图表内使用 style 和 size 控制 两个变量**,因为当形状改变了之后,大小的区分变得不够直观。比如下图 (Figure 3.2-4):
```{python}
# 同时使用 (hue + style) 和 size 控制 岛屿 和 鳍长 两个变量
ax = sns.scatterplot(
data=df,x='bill_length_mm',y='bill_depth_mm', # 散点图:企鹅喙长-喙深
hue='island',
style='island',
size='flipper_length_mm', # 在 Figure 3.2-3 的基础上增加了对于点大小的区分
)
sns.move_legend(ax,loc='upper left',bbox_to_anchor=(1,1)) # 移动图例
plt.figtext(0.5,-0.1,"Figure 3.2-4. Size: controlling another variable 'flipper_length_mm'",
ha="center",fontsize=10,style='italic')
plt.show()
```
**还有一些其他细节需要注意:**
- 使用颜色时应当尽量兼顾色觉缺陷读者,尽量选择 **在色相和明度上均有明显差异** 的颜色。\
- 虽然对于点形状的区分常应用于散点图,然而并不一定适用于其他图,比如折线图。**当折点过多时,不宜在折线图中展示点。**
这些细节我们将在后续章节 <a href="#4-折线图-line-plot">4. 折线图 Line Plot</a> 中继续深入讨论。
\*\*
<h2 id="3.3-对数尺度-logarithmic-scales">
3.3 对数尺度 Logarithmic Scales
</h2>
\*\*
**对数尺度 (logarithmic scale)** 是一个非线性的测量尺度,适用于有较大范围差异的数据。比如里氏地震震级、声学中的音量、光学中的光强度、及溶液的PH值等。为这类数据绘制散点图时,可以将坐标轴使用的刻度尺度设置为对数尺度(默认为线性尺度,如 Figure 4 中横坐标为 35, 40, 45, 50... 是线性增长的数字),这样会让原本拥挤的数据点变得较为分散、均匀,更容易观察。([维基百科 - 对数尺度](https://zh.wikipedia.org/wiki/%E5%B0%8D%E6%95%B8%E5%B0%BA%E5%BA%A6#cite_ref-1))
Wilke (2019, p.17) 使用 $(1, 3.16, 10, 31.6, 100)$ 这组数据作为例子画了四个数轴 (Figure 3.3-1)。其中:\
\> $10 ^ {0.5} = \sqrt{10} \approx 3.16$\
\> $10^{1.5} = 10 \times 10^{0.5} \approx 31.6$

*Figure 3.3-1. 四个数轴 (Wilke, 2019, p.17)*
如 Figure 3.3-1 所示:
第一个数轴使用了线性尺度,刻度为 $(0, 25, 50, 75, 100)$,数据点不均匀地分布在数轴上,每个点代表对应的 x 的数值。每个点的值分别为:$1, 3.16, 10, 31.6, 100$ 。
第二个数轴 **同样使用了线性尺度**,刻度为 $(0.0, 0.5, 1.0, 1.5, 2.0)$ ,但是在原数据的基础上 **进行了取对操作**。第二个数轴中每个点代表 x 的对数,即 \$ log\_{10}(x) \$ (或 “\$ lg(x)\$” )。每个点的值分别为:$0.0, 0.5, 1.0, 1.5, 2.0$ 。此时每个数据点代表的数值 **已经不是原数据,而是其对数**,因此第二个数轴的标签为 “ \$ log\_{10}(x) \$ ” 。
第三个数轴 **仍然使用了原数据** ,但是对于轴的尺度进行了调整——**改用了对数尺度**,刻度为 $(1, 3.16, 10, 31.6, 100)$ ,约等于 \$ (10\^{0.0} $,$ 10\^{0.5} $,$ 10\^{1.0} $,$ 10\^{2.0}) \$ 。
第一个数轴和第三个数轴对比来看,对于同一组数据,轴刻度使用了不同尺度(线性尺度 v.s. 对数尺度),数据点在轴上的排布发生了变化——**线性尺度轴中分布不均匀的点,在对数尺度轴中变得均匀**。这样调整数轴的刻度,有助于我们观察分布不均匀的数据,尤其是呈现指数型增长趋势的数据(i.e. 先增长得很慢、数据点挤在一起;后增长得很快,数据点间距突增)。
\*\*
<p style="color:FireBrick">
需要注意的是,改用对数尺度后,只是让轴刻度的展示方式变了,数据点的位置有所变化,但并没有改变数据点的值。
</p>
\*\*
也就是说,第一个数轴和第三个数轴展示的都是原数据 x,而只有第二个数轴展示的是 x 的对数。\
因此,对于像第三个数轴这样的 仅改用刻度尺度 但不改动原数据 的图而言,不可以将轴标题写作 “ \$ log\_{10}(x) \$ ” (见第四个数轴)。
**总地来说,当数据的分布具有以下特性时,用对数尺度来表示轴刻度会更方便观察:**\
\* 数据有数量级差异时,使用对数尺度可以同时显示很大的数值和很小的数值。\
\* 数据有指数型增长趋势时,使用对数尺度可以将曲线变为直线表示。
例如,下图 (Figure 3.3-2) 中使用的数据范围差异较大且左边过于集中、右边过于空旷——可以考虑使用对数尺度的坐标轴 (Figure 3.3-3)。
```{python}
# 用 seaborn 中的另一个示例数据集 'planets' 作为演示
# 展示 “行星到地球的距离” 和 “行星的质量” 之间的关系
planets = sns.load_dataset('planets')
g = sns.scatterplot(data=planets, x='distance', y='mass')
plt.title('Relationship between planetary distance and mass')
plt.figtext(0.5,-0.1,"Figure 3.3-2. Point plot: linear scale",ha="center",fontsize=10,style='italic')
plt.show()
```
```{python}
# 改用对数尺度重新画散点图
planets = sns.load_dataset('planets')
g = sns.scatterplot(data=planets, x='distance', y='mass')
# x/y 轴都设置对数刻度标尺
g.set_xscale('log') # 默认底数为 10,可以通过设置 base 参数来修改底数。
g.set_yscale('log')
plt.figtext(0.5,-0.1,"Figure 3.3-3. Point plot: logarithmic scale",ha="center",fontsize=10,style='italic')
plt.show()
```
> ***注意:***\
> *Figure 3.3-3 中,刻度* $(10^0, 10^1, 10^2, 10^3 ... 10^n)$ 是等距离的对数尺度刻度。而每两个大刻度中间的小刻度代表了等差的实际数值,比如从原点 (原点为 $10^0$,即 1) 开始到 $10^1$ 为止的九个小刻度分别代表了数字 $2, 3, 4, ..., 8, 9$,从 $10^1$ 到 $10^2$ 之间的九个小刻度分别为 $20, 30, 40, ..., 80, 90$,以此类推。
由于对数尺度的特性,对数尺度轴上没有 0 值,而是以 1 (即底数的 0 次方) 为原点,其正半轴为大于 1 的数,负半轴为大于 0 小于 1 的数。因此,**对数尺度适合用于展示一些比例数据**。比如 Wilke (2019, pp.18-20) 展示了一组数据记录了德克萨斯州每个县的人口数量,并将其除以德克萨斯州所有县的人口中位数,作为纵轴数据。利用对数尺度 (Figure 3.3-4),展现了德克萨斯州每个县人口数在中位数附近的分布情况,当比值为 1 的时候,说明该县的人口正好为中位数。

*Figure 3.3-4. 德克萨斯州各县人口分布情况 - 对数尺度*
然而,如果用线性尺度展示 Figure 3.3-3 中的数据的话,就会以 0 为原点,无法清晰展示数据在 1 两侧的分布情况,形成 Figure 3.3-5。

*Figure 3.3-5. 德克萨斯州各县人口分布情况 - 线性尺度*
[**总地来说,对数尺度的优点有:**]{style="color:FireBrick"}\
\* **压缩数据范围。** 用于处理大范围数据,避免极大和极小数据因为距离相差甚远而难以展示和阅读。 \* **使数据分布均匀。** 避免大量数据点集中在特定范围内而难以阅读。 \* **揭示指数增长趋势。** 如果原数据呈现指数增长趋势,对数尺度会让数据呈直线关系,更容易发现变量之间的关联性。 \* **突显相对差异。** 当数据的绝对值非常大时,不同数据点之间的数量级差可能比绝对值差更有研究价值。比如 $10^5$ 和 $10^8$ 之间差了三个数量级。
[**而对数尺度也存在局限性:**]{style="color:FireBrick"}\
\* **不适用于零值和负值。** 由于对数函数的定义,对数尺度轴中只有正数,没有 0 和 负数。\
\* **难以解读。** 对数尺度图表不像线性尺度那样直观易懂,不熟悉对数尺度的读者可能难以解读对数尺度图表。\
\* **对于非指数关系的展示不直观。** 如果数据本身的趋势并不符合指/对数关系,使用对数尺度可能会误导读者,掩盖其真实趋势。
\*\*
<h2 id="3.4-回归图-regression-plot">
3.4 回归图 Regression Plot
</h2>
\*\*
散点图通常用于探究两个(或多个)变量之间的数学关系,回归图 (regression plot) 则是将散点图拟合成一条线,用于展示两个变量之间的关系。最常见的拟合方式是线性拟合 (linear fitting),即,将散点图拟合成一条直线,这条线称作线性回归线 (linear regression line)。置信区间用于显示回归线(作为估计值)的不确定性,当置信水平为 95% 时,真实值有 95% 的可能落在这个区间内。Figure 3.4-1 中,直线是线性回归线,阴影部分是置信区间。
```{python}
# 使用 sns.lmplot() 函数画一个包含线性拟合的散点图
sns.lmplot(data=df, x='bill_length_mm', y='bill_depth_mm', hue='sex')
#【lmplot】linear model plot
# 该函数默认的线性拟合方式是 'ci',即 置信区间 (confidence intervals)。
# 默认置信水平为 95%,即 “真实值有 95% 的概率落在这个区间内”,用于衡量估计值(即回归线)的不确定性。
# ⭕注:此函数仅适用于离散型数据。
plt.figtext(0.5,-0.1,"Figure 3.4-1. Regression Plot",ha="center",fontsize=10,style='italic')
plt.show()
```
\*\*
<h1 id="4-折线图-line-plot">
4. 折线图 Line Plot
</h1>
\*\*
在散点图中,数据点以点的形式独立存在,显示变量之间的关系或分布。通常用于探索 **两个变量** 之间的相关性或分布情况。其数据点之间通常无先后关系。
而在折线图中,数据点通过线段连接,强调数据的连续性或变化趋势。因此折线图通常用于时间序列数据,强调 **一个变量** 随时间的变化趋势。其数据点之间存在先后关系。
如下图 (Figure 4-1),展示了某航空公司每月乘客量遂年份增长的变化:
```{python}
# 画用颜色区分过的折线图
sns.lineplot(
data=flights, x='year', y='passengers', # 画乘客量遂年份增长的变化折线图
hue='month', # 用颜色区分月份
)
#【注】虽然年份和人数都不是严格的连续数据,但是当数据量足够多时,足以体现连续的趋势,因此可以使用折线图展示变化趋势。
plt.figtext(0.5,-0.1,"Figure 4-1. Line plot: with hue",ha="center",fontsize=10,style='italic')
plt.show()
```
也可以通过设置 `markers = True` 和 `dashes = False` 来展示折点,如下图 (Figure 4-2):
```{python}
# 同时用颜色和点形状区分
sns.lineplot(
data=flights, x='year', y='passengers',
hue='month', style='month', # 同时使用 颜色 和 点/线形状 区分月份
markers=True, # 在线上显示不同形状的点,需要和 style 联用
dashes=False, # 不用虚线
)
plt.figtext(0.5,-0.1,"Figure 4-2. Line plot: with hue & style",ha="center",fontsize=10,style='italic')
plt.show()
```
但是,当折点很多时,不建议在折线图中展示折点,过多的折点会阻碍阅读;相反,清晰的一条线更能彰显数据随时间的变化趋势 (Wilke, 2019, pp. 135-137)。
如果通过 Seaborn 绘制点图 (point plot),也可达到类似的效果,见下图 (Figure 4-3):
```{python}
# 用点图达到类似效果
sns.pointplot(data=flights, x='year', y='passengers', hue='month')
plt.figtext(0.5,-0.1,"Figure 4-3. Point plot: passenger volume trend over time",
ha="center",fontsize=10,style='italic')
plt.show()
```
但是,`sns.pointplot()` 函数不可用不同点形状区分其他变量,也不可改变点大小,更不可去除点。\
因此,要想观察一个变量随时间变化的趋势,最好选择 `sns.lineplot()` 而不是 `sns.pointplot()`。
此外,当 y 轴变量在每个时间点上有不止一个值,且没有用其他参数(如颜色)对其进行区分时,用 `sns.lineplot()` 画折线图会自动生成一条平均值折线和误差区间(默认置信水平 95%),见下图 (Figure 4-4)。
```{python}
# 不做任何区分则生成平均值折线
sns.lineplot(data=flights, x='year', y='passengers')
# Figure 4-4 中,同一 x 坐标上(即同年内),上边缘值是旺季乘客量,下边缘是淡季乘客量
plt.figtext(0.5,-0.1,"Figure 4-4. Line plot: without hue / style",ha="center",fontsize=10,style='italic')
plt.show()
```
[**在折线图中使用颜色区分不同的线条时,需要注意:**]{style="color:FireBrick"}\
\* **图例颜色顺序应当符合线条颜色顺序**\
\* **选择的颜色尽量兼顾患有色觉缺陷的读者**
如下面的 Figure 4-5 所示,图例和线条颜色顺序不一样,会增加阅读困难,这样的图例被 Wilke (2019, p.248) 认为是差的图例。

*Figure 4-5. 差图例:图例和线条颜色顺序不匹配*
相反,图例和线条颜色顺序相符的折线图被 Wilke (2019, p.249) 认为是好的图表,如 Figure 4-6 所示。

*Figure 4-6. 好图例:图例和线条颜色顺序匹配(且选色兼顾色觉缺陷读者)*
Wilke (2019, p.250) 还展示了不同色觉缺陷模拟下的 Figure 4-6 图表,以及去除饱和度的图表,如 Figure 4-7 所示:

*Figure 4-7. 不同色觉缺陷模拟 & 去饱和度下的图表(分别为:绿色弱,红色弱,蓝色弱,去除饱和度)*
由 Figure 4-7 可见,Figure 4-6 中的图表使用的颜色,对于三种色觉缺陷患者而言都可以区分;并且在去除饱和度的情况下,也能通过明度不同加以区分。由于色觉缺陷患者眼中的这些颜色虽然有区别但是区别很微妙,图例和线条颜色顺序相匹配显得尤为重要。
除此之外,Wilke (2019, p.251) 还建议 **进一步缩小折线图的阅读难度——去除图例,直接在折线旁标注文字。** 如下图 (Figure 4-8) 所示:

*Figure 4-8. 去除图例,直接在折线旁边标注文字*
如 Figure 4-8,这样操作节省了读者对照图例的工作量,让图表更易读。但是这种操作通过 Seaborn 实现起来较为困难,本门课程中不必使用。用 Figure 4-6 中的符合颜色顺序的图例即可。
\*\*
<h1 id="5-热力图-heatmap">
5. 热力图 Heatmap
</h1>
\*\*
\*\*
<h2 id="5.1-数据透视表-枢轴表-pivot-table">
5.1 数据透视表 (枢轴表) Pivot Table
</h2>
\*\*
在绘制热力图之前,我们需要先给原数据创建一个 pivot table(数据透视表,又称“枢轴表”)。数据透视表将原表格中的多个 (两个) 变量以矩阵的形式展现,即,列名是一个变量,行名是另一个变量。
pivot 操作 将原表某列中的所有数据种类转变为新的列名 (column label) 或 行名/索引 (index)。如下表 (Table 5.1-2) ,把原表 (Table 5.1-1) 的 'year' 列中的所有数据种类(1949\~1960)变为新的列名;同理,将另一列 ('month') 中的所有数据种类转变为新的行名。
pivot 操作和 melt 操作相反,pivot 将 “长表格” 变为 “宽表格”,而 melt 将 “宽表格” 变为 “长表格”。melt 操作会将原本的列名变为表格内的数据值,从而让表格变得更“长”(行数更多)。
```{python}
flights.head() # 原飞行乘客表
```
*Table 5.1-1. 原飞行乘客表 (预览前五行)*
```{python}
# 创建一个数据透视表 (pivot table)
flights_pivot = pd.pivot_table(
flights, # 以 flights 表格为原数据
index='month', # 让 'month' 列中的数据种类作为新行名
columns='year', # 'year' 列中的数据种类作为新列名
values='passengers', # 'passenger' 列中的数据作为新表内部的数据
observed=False, # 显示所有分类变量的可能组合(即使有些组合在原数据中可能未出现)。
# 此处所有组合在原表中都出现了,所以新表中没有 NaN 数据。
)
# ⭕注: 由于要创建的数据透视表是一个矩阵的形式,所以也可以给变量命名为 matrix,此处命名为 flights_pivot。
```
```{python}
flights_pivot # 查看刚刚创建的数据透视表
```
*Table 5.1-2. 数据透视表:年 & 月 - 乘客量*
**注:**
`pd.pivot_table()` 函数默认的 `aggfunc` 参数 (aggregation function 的缩写) 为 `'mean'`,即,当生成的透视表中,一个单元格对应的原数据不止一组时,默认求元数据的平均值作为透视表单元格内数据。
此处 (Table 5.1-1 和 Table 5.1-2) 使用了 flights 数据表,该表中,特定 year 和 month 下,对应的 passenger 只有一个数据,所以生成数据透视表时不用求平均值。
然而,像 penguins 数据表,如下表(Table 5.1-3):
```{python}
df.head()
```
*Table 5.1-3. 原企鹅数据表(预览前五行)*
可以看出,企鹅数据表中,同一种类、同一岛屿的企鹅不止一只(即,observation 不止一行),但是它们在数据透视表 (如 Table 5.1-4) 中只对应一个单元格,因此默认求其平均值。
```{python}
# 用企鹅数据集中的 种类 和 岛屿 两列 制作数据透视表
df_pivot=pd.pivot_table(
df, # 以 df (即 penguins) 表格为原数据
index='species',
columns='island',
values='bill_length_mm',
)
```
```{python}
df_pivot
```
*Table 5.1-4. 数据透视表:企鹅种类 & 岛屿 - 鳍长*
\*\*
<h2 id="5.2-绘制热力图">
5.2 绘制热力图
</h2>
\*\*
使用 Table 5.1-2 绘制热力图,见 Figure 5.2-1:
```{python}
# 用刚生成的透视表 (Table 5.1-2) 画热力图
sns.heatmap(data=flights_pivot, cbar_kws={'label':'passengers'})
#【data】
# .heatmap 直接使用矩阵形式的表格画图,而不是通过指定 x/y 参数为原 dataframe 中的特定列来画图。
#【cbar_kws】
# colorbar keyword arguments 彩色条关键字参数。此处设置了色彩条的标签。
plt.figtext(0.5,-0.1,"Figure 5.2-1. Heatmap: flights",ha="center",fontsize=10,style='italic')
plt.show()
```
还可以通过设置 `sns.heatmap()` 函数中的 其他参数(如:`cmap`,`annot`)来进一步修改热力图,如下图(Figure 5.2-2):
```{python}
# 设置热力图的其他参数
sns.heatmap(
data=flights_pivot, cbar_kws={'label':'passengers'},
cmap='viridis', # 更改使用的 colormap(Matplotlib 中预制的 colormap)
annot=True, # annotation,给热力图格子添加注释,显示 data 使用的表格中的数据
fmt = '.0f', # format,和 annot 联用。'.nf'是用于更改浮点数格式的代码,
# 意为 “保留到第n位小数”,此处 n=0,即为保留整数。
)
#【cmap】
# colormap。设置热力图使用的颜色图 (colormap)。
# 可以使用 Seaborn 或 Matplotlib 中预制的 color palette 或 colormap 名称,
# 如:'crest','flare', 'viridsis','pink' 等。
plt.figtext(0.5,-0.1,"Figure 5.2-2. Heatmap: flights (added more arguments)",
ha="center",fontsize=10,style='italic')
plt.show()
```
同理,也可以使用 Table 5.1-4 绘制热力图,见下图 (Figure 5.2-3):
```{python}
sns.heatmap(data=df_pivot,cmap='crest',cbar_kws={'label':'bill_length_mm'},annot=True)
plt.figtext(0.5,-0.1,"Figure 5.2-3. Heatmap: penguins",ha="center",fontsize=10,style='italic')
plt.show()
```
\*\*
<h1 id="6-二维直方图-2-dimensional-histogram">
6. 二维直方图 2-dimensional histogram
</h1>
\*\*
根据 Wilke (2019, pp. 222-225) 介绍,我们可以使用含有半透明点的散点图展示数据在两个变量控制下的分布情况,然而如果数据点过多、过密,就会导致散点图难以展示整体数据分布。如下图 (Figure 6-1) 点密度高的区域将显示为深色的均匀斑点,而在点密度低的区域中,各个点几乎不可见。

*Figure 6-1. 数据点过多、过密的散点图 (Wilke, 2019, p. 223)*
此时,我们可以改用 **二维直方图/2D直方图 (2-dimenl histogram)**,而不是绘制单个点(散点图)。二维直方图将整个 x - y 平面细分为小矩形,每个矩形是一个分箱 (bin),并计算落入每个分箱的数据量,然后按照数据量的大小对矩形进行着色。如下图 (Figure 6-2):
```{python}
# 绘制 2D 直方图
sns.histplot(
data=df, x='bill_depth_mm', y='bill_length_mm',
cbar=True, #【cbar】colorbar。cbar 为 True 时,展示色彩条。
cbar_kws={'label': 'count'}, # 给色彩条添加标签 'count'
)
plt.figtext(0.5,-0.1,"Figure 6-2. 2D histogram",ha="center",fontsize=10,style='italic')
plt.show()
```
**下表 (Table 6-1) 展示了热力图和二维直方图的区别:**

*Table 6-1. 热力图和二维直方图的区别*
\*\*
<h1 id="7-双变量图-joint-plot">
7. 双变量图 Joint Plot
</h1>
\*\*
利用 Seaborn 的 `sns.jointplot()` 函数,我们可以画一个双变量图,同时展示包含两个变量的二元分布图,和这两个变量各自的一元分布图。
如下图 (Figure 7-1),我们可以在展示二维直方图 (同 Figure 6-2) 的同时,展示两个变量各自的一维直方图。
```{python}
# 双变量图:直方图
sns.jointplot(data=df, x='bill_depth_mm', y='bill_length_mm', kind='hist')
#【kind】默认为 'scatter',即,图中间的二元分布图(大图)默认为散点图形式(如 Figure 7-3)。此处设置为直方图了。
plt.figtext(0.5,-0.1,"Figure 7-1. Joint Plot: histograms",ha="center",fontsize=10,style='italic')
plt.show()
```
还可以通过控制参数 `kind='hex'` 来让中间的各自呈六边形,如下图 (Figure 7-2):
```{python}
# 双变量图:六边形图
sns.jointplot(data=df, x='bill_depth_mm', y='bill_length_mm', kind='hex')
#【kind='hex'】hexagonal。让中间的二元分布图呈六边形。
plt.figtext(0.5,-0.1,"Figure 7-2. Joint Plot: hexagonal histogram",ha="center",fontsize=10,style='italic')
plt.show()
```
还可以展示其他形式的分布图,如下图 (Figure 7-3):
```{python}
# 双变量图:用颜色区分
sns.jointplot(data=df, x="bill_depth_mm", y="bill_length_mm",hue="species")
#【hue】用颜色区分企鹅种类。
#【⭕注】此处由于使用了 hue,外部的一元分布图自动变为密度图形式。
plt.figtext(0.5,-0.1,"Figure 7-3. Joint Plot: separated by hue",ha="center",fontsize=10,style='italic')
plt.show()
```
还可以通过设置参数 `kind='kde'` (abbr. 'kernal density estimation') 来生成自动光滑化的分布曲线,如下图 (Figure 7-4)。但是由于光滑化后的曲线并非真实数据,可能会误导读者,尤其是当数据点量非常少的时候。因此不建议在本课程中使用。
```{python}
# 双变量图:用颜色区分
sns.jointplot(data=df, x="bill_depth_mm", y="bill_length_mm",hue="species",kind='kde')
plt.figtext(0.5,-0.1,"Figure 7-4. Joint Plot: artifitially smoothed (kde)",
ha="center",fontsize=10,style='italic')
plt.show()
```
\*\*
<h1 id="8-配对图-pair-plot">
8. 配对图 Pair Plot
</h1>
\*\*
使用 Seaborn 的 `sns.pairplot()` 函数可以轻松画出原数据表中多个变量(即,原数据表中的多列)各自两两配对的分布图表,进而形成一个图表阵。如下图(Figure 7-4):
```{python}
# pair plots
sns.pairplot(data=df, hue='species',height=1.7) # height: 调整图片大小(只有高度和宽高比,没有宽度)
plt.figtext(0.5,-0.1,"Figure 7-4. Pair Plot",ha="center",fontsize=10,style='italic')
plt.show()
```
Figure 7-4 中,原 DataFrame 中的四个 ratio 变量(列)被自动识别,并作为数据画图。其中对角线的图是这四个变量各自的一元分布图,而除此之外的每个子图表都是基于一对变量(两个变量)绘制出的二元分布图。
同理,我们可以通过设置参数 `diag_kind` 和 `kind` 来修改对角线图表和其他二元图表的格式,如下图 (Figure 7-4)。
```{python}
# 加入两句 keyword arguments
sns.pairplot(
data=df,
hue='species',
diag_kind='hist', # kind of plot for the diagonal subplots 对角线图表的形式
kind='hist', # 每个二元分布图的形式(即,除了对角线之外的所有图表)
height=1.7 # 调整图片大小
)
plt.figtext(0.5,-0.1,"Figure 7-4. Pair Plot: histograms",ha="center",fontsize=10,style='italic')
plt.show()
```
<a href="#top" id="back-to-top"><u>⇧ 回到页面顶部</u></a>